Automatická klasifikace prostorových dat
Petr Kuba, Luboš Popelínský
Fakulta informatiky. Masarykova universita
Botanická 68a, 602 00 Brno
Email: xkuba@fi.muni.cz, popel@fi.muni.cz
Abstrakt
Dolování znalostí se definuje jako hledání znalosti skryté v uložených datech. Pojednáváme o použití jedné z metod dolování znalostí — automatické klasifikaci — k dolování v prostorové relační databázi. Tato metoda používá k reprezentaci dat grafy sousednosti. Ukážeme použití prostorové klasifikace na datech o okresech České republiky.
Úvod
Dolování znalostí z prostorových dat je bezpochyby velmi potřebné. Standardní metody používané pro neprostorová data se však pro tuto úlohu většinou nehodí. Při vyhledávání znalostí v prostorových datech je třeba pracovat nejen s popisnou informací, ale i s prostorovou složkou dat. Naším cílem proto bylo vyzkoušet možnosti úpravy jedné z nejčastěji používaných metod dolování dat — automatické klasifikace — pro práci s prostorovými daty.
Úloha prostorové klasifikace spočívá v zařazení objektu do některé z konečného počtu tříd na základě jeho vlastností. Klasifikátor samotný se vytváří z učící množiny, tj. ze vzorku dat se známou klasifikací.
Klasifikátor může být vytvořen pomocí neuronové sítě, metodami strojového učení nebo statistickými metodami. V tomto příspěvku se zabýváme metodou rozhodovacích stromů [6].
V kapitole 2 nejprve krátce charakterizujeme metodu reprezentace prostorových objektů pomocí grafů sousednosti [3]. Úloha prostorové klasifikace je popsána v kapitole 3. V kapitole 4 popisujeme použitá data o okresech České republiky. Vlastní implementaci je věnována kapitola 5. Konečně získané výsledky jsou popsány v kapitolách 6.1 a 6.2.
Grafy sousednosti
Graf sousednosti G pro prostorovou relaci soused/2 je graf G (U, H), kde U je množina uzlů a H množina hran. Každý uzel reprezentuje objekt a dva uzly N1, N2 jsou spojeny hranou právě tehdy, když dva objekty jsou v relaci soused. Relace soused může vyjadřovat např. následující:
Cesta v grafu sousednosti pro nějaký graf G je seznam uzlů z G, kde každý pár následujících uzlů z cesty je spojen nějakou hranou z G, tj. Pro cestu [n0, n1, ..., nk-1] musí v G existovat hrany (ni, ni+1) pro každé 0 £ i < k-1.
Základní operace:
Použili jsme implementaci uvedených funkcí z [4]. Tato implementace pracuje nad objektově relačním databázovým systémem PostgreSQL [2], který je volně šiřitelný a existuje pro většinu běžných operačních systémů (Windows, Irix, Solaris, ...) a je též součástí operačního systému Linux. Prostorová data, grafy sousednosti a cesty v grafech sousednosti jsou uloženy v tabulkách Postgresu. Popsané funkce jsou implementovány jako funkce Postgresu.
Prostorová klasifikace
Mějme množinu objektů, které jsou popsány svými atributy. Dále je prokaždý objekt dána třída, do které tento objekt patří.
Úlohu prostorové klasifikace budeme ilustrovat následujícím příkladem [1]:
|
Jméno |
Rozloha |
Obcí |
Obyvatel |
Nezaměstanost |
|
Blansko |
942 |
129 |
107973 |
stredni |
|
Brno_mesto |
230 |
1 |
384396 |
nizka |
|
Brno_venkov |
1109 |
137 |
158398 |
nizka |
|
Vyskov |
889 |
80 |
86752 |
stredni |
|
Prostejov |
770 |
95 |
110088 |
stredni |
|
Prerov |
884 |
103 |
136845 |
vysoka |
|
Olomouc |
1451 |
93 |
225599 |
stredni |
Tabulka obsahuje objekty Okresy ČR, které jsou popsány atributy Jméno, Rozloha, Obcí (počet obcí) a Obyvatel (počet obyvatel). Poslední sloupec Nezaměstnanost určuje třídu, do které objekt spadá.
Úkolem klasifikace je najít rozhodovací strom (případně množinu rozhodovacích pravidel), který pro každý objekt na základě jeho atributů rozhodne, do které třídy patří. Rozhodovací strom konstruujeme na základě učící množiny. Očekává se, že takový strom bude dobře klasifikovat všechny příklady, tedy i ty, které se nevyskytly v učící množině. Nalezení optimálního rozhodovacího stromu je exponenciálně složité vzhledem k počtu atributů a počtu jejich hodnot. Využívají se proto heuristiky založené zpravidla na odhadu informace obsažené v jednotlivých atributech [8].
Pro data z předchozí tabulky vypadá rozhodovací strom například takto:
obyvatel <= 110088 : stredni (3.0/0.0)obyvatel > 110088 :
| obyvatel <= 136845 : vysoka (1.0/0.0)
| obyvatel > 136845 :
| | rozloha <= 1109 : nizka (2.0/0.0)
| | rozloha > 1109 : stredni (1.0/0.0)
Název atributu představuje uzel a jednotlivé výrazy představují větve. Každý objekt se vydá po té větvi, jejíž podmínka je pro něj splněna. Názvy tříd představují listy stromu. Například objekt Brno_mesto z předchozího příkladu se klasifikuje takto: v prvním uzlu je splněna podmínka obyvatel > 110088, objekt se tedy vydá po této větvi. V dalším uzlu je splněna podmínka obyvatel > 136845 a v dalším rozloha £ 1109. Objekt tedy spadá do třídy nízká. Z čísel v závorkách u názvu třídy vždy první udává, kolik objektů bylo klasifikováno do této třídy, a druhé, kolik bylo klasifikováno chybně.
Při prostorové klasifikaci neuvažujeme při tvorbě rozhodovacího stromu pouze atributy objektu, ale také atributy jeho sousedů, tj. objektů na cestě v grafu sousednosti, která vychází z daného objektu. Za sousedy tedy nepovažujeme pouze objekty sousedící s daným objektem přímo (jejich hranice se dotýkají), ale i ty, které leží na cestě dále od objektu (nepřímí sousedé). Kromě vlastních dat o objektech musíme tedy mít k dispozici také informaci o tom, které objekty spolu sousedí - graf sousednosti. Potom definujeme generalizovaný atribut objektu jako dvojici (jméno_atributu, index), kde index je pozice sousedícího objektu v cestě - vzdálenost od objektu, objekt sám má index 0 - a jméno_atributu je jeho atribut.
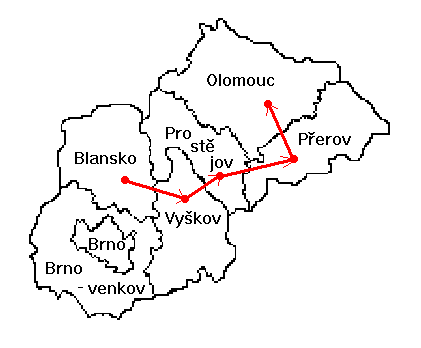
Obr. 1: Mapa okresů
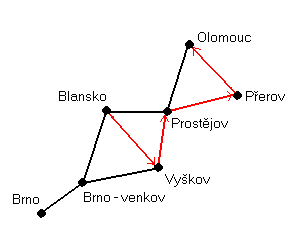
Obr. 2: Graf sousednosti
Na obr. 2 je graf sousednosti pro okresy z obr. 1. Je zde také zakreslena jedna z~možných cest v grafu sousednosti vycházející z okresu Blansko. Objekt Blansko má pak tyto tyto generalizované atributy:
(jmeno, 0), (rozloha, 0), ¼
- jeho vlastní atributy
(jmeno, 1), (rozloha, 1), ¼
- atributy přímého souseda, tj. okresu Vyškov
(jmeno, 2), (rozloha, 2), ¼
- atributy dalšího objektu na cestě, tj. okresu Prostějov
Data o nezaměstnanosti v České republice
Ukážeme nyní použití popsané techniky na statistických datech, která se týkají okresů České republiky cite{stat}. Data obsahují celkem 77 objektů. Atributy byly vybrány tak, aby popisovaly okres z co nejvíce hledisek (v závorkách je uvedena průměrná hodnota atributu):
jmeno - jméno okresu
rozloha - rozloha okresu (1031)
obci - počet obcí v okresu (82)
pristehovanych - počet osob přistěhovaných na území okresu (271)
vystehovanych - počet osob vystěhovaných z území okresu (239)
obyvatel - počet obyvatel okresu (119632)
zamestnancu - počet zaměstnanců v okresu (30961)
mzda - průměrná měsíční mzda v okresu (10479)
nezam_1_misto - počet nezaměstnaných na 1 volné pracovní místo (17)
dokon_bytu - počet dostavěných bytů (57)
staveb_prace - objem stavebních prací (383)
RES - počet jednotek v registru ekonomických subjektů (19887)
Dále máme tabulku popisující graf sousednosti, která obsahuje dvojice sousedících okresů.
Naším cílem je najít rozhodovací strom, který by určil nezaměstnanost na základě ostatních atributů. Nezaměstnanost klasifikujeme do tří tříd nízká (nezaměstnanost < 7%), střední} (7% £ nezaměstnanost < 13%) a vysoká (nezaměstnanost £ 13%). Maximální délku cest je vhodné omezit, neboť vliv sousedů na objekt zpravidla klesá s rostoucí vzdáleností. Můžeme předpokládat, že lidé necestují za prací dále než do sousedního okresu. Proto budeme pracovat s cestami délky 1, tedy budeme uvažovat pouze přímé sousedy okresů.
Implementace
K implementaci jsme použili relační databázi PostgreSQL [2] a program pro klasifikaci C4.5 [8].
Zpracovávaná data jsou uložena v tabulce v Postgresu. Kromě popisných atributů má navíc každý objekt atribut id, který jej jednoznačně identifikuje. Dále je v databázi uložena tabulka nGraph reprezentující graf sousednosti objektů reprezentovaných atributem id. Z této tabulky vytvoří funkce create_Paths (popsaná výše) cesty v grafu sousednosti tvořené posloupností identifikátorů id (tabulka nPaths).
Z tabulky popisující objekty a z tabulky s cestami vytvoříme pomocí operace select tabulku připravenou pro zpracování systémem C4.5, která bude obsahovat všechny generalizované atributy pro každý objekt:
create table c45data as
select o0.attr1, ..., o0.attrk,
o1.attr1, ..., o1.attrk,
...
on.attr1, ..., on.attrk
from data o0, data o1, ..., data on,
nPaths p
where list_nitem(p.npath, 0) = o0.id and
list_nitem(p.npath, 1) = o1.id and
...
list_nitem(p.npath, n) = on.id;
kde oi jsou objekty na cestě v grafu sousednosti a attrj jsou jejich atributy. Formát tohoto dotazu zůstává stále stejný, pouze se mění počet objektů a jména a počet atributů.
Pro načtení dat z databáze do C4.5 jsme využili [5]. Jedná se o úpravu C4.5, která umožňuje načítat vstupní data přímo z databáze Postgresu.
Výsledky
Vliv sousedních okresů
Pokud ke klasifikaci použijeme pouze atributy sousedních okresů, dostáváme rozhodovací strom, který rozhoduje převážně podle jména sousedního okresu. Vzhledem k tomu, že atribut jméno okresu má hodně hodnot, je tento strom velmi rozsáhlý (asi 170 řádků). Chybovost tohoto stromu, tj. počet chybně klasifikovaných objektů, je 33%.
Po vynechání atributu (jmeno, 1) dostáváme následující strom:
(nezam_1_misto, 1) <= 33.1 :
| (vystehovanych, 1) <= 147 :
| | (zamestnancu, 1) <= 8196 : stredni (2.0/1.0)
| | (zamestnancu, 1) > 8196 : nizka (55.0/23.0)
| (vystehovanych, 1) > 147 :
| | (staveb_prace, 1) <= 408 : stredni (236.0/87.6)
| | (staveb_prace, 1) > 408 :
| | | (rozloha, 1) <= 1451 : nizka (26.0/12.3)
| | | (rozloha, 1) > 1451 : stredni (6.0/3.3)
(nezam_1_misto, 1) > 33.1 :
| (RES, 1) <= 17599 : vysoka (3.0/1.1)
| (RES, 1) > 17599 : stredni (40.0/16.7)
Jeho chybovost je 35%. Ze stromu můžeme přečíst například následující znalosti:
Pokud počet nezaměstnaných na jedno volné místo v sousedních okresech je větší než 33.1 (tedy silně nadprůměrný) a počet ekonomických subjektů v sousedních okresech je menší nebo rovna 17599 (tedy podprůměrný), tak nezaměstnanost v okrese je vysoká.
Pokud počet nezaměstnaných na jedno volné místo v sousedních okresech je menší nebo roven 33.1, počet vystěhovalých ze sousedních okresů je menší nebo roven 147 (podprůměrný) a počet zaměstnanců v sousedních okresech je větší než 8196, tak nezaměstnanost je nízká.
Podíváme-li se na oba celé podstromy (nezam_1_misto, 1), můžeme říct, že pokud je počet nezaměstnaných na jedno volné místo v sousedních okresech menší nebo roven 33.1, tak nezaměstnanost v okrese je nízká nebo střední. Pokud je naopak větší než 33.1 (tj. silně nadprůměrný), tak nezaměstnanost je střední nebo vysoká. S rostoucím počtem nezaměstnaných na 1 volné místo v okolí okresu tedy roste míra nezaměstnanosti v okresu.
Můžeme si také všimnout, že některé atributy se ve stromu vůbec nevyskytly. Znamená to, že jejich vliv na nezaměstnanost je malý nebo žádný. Jedná se o atributy obci, pristehovanych (přitom atribut vystehovanych se ve stromě vyskytuje), obyvatel, mzda a dokon_bytu.
Výsledky pro úplnou množinu atributů
Nalezený rozhodovací strom má poměrně velkou chybovost. Ta může být způsobena jednak příliš velkým počtem atributů vzhledem k počtu příkladů (tzv. overfitting), jednak malou vypovídací schopností atributů sousedních okresů. Zkusili jsme tedy přidat některé vlastní atributy objektu a některé atributy sousedů odebrat.
Pokud ke klasifikaci použijeme všechny generalizované atributy objektu, pak se ve stromu vyskytují téměř výhradně vlastní atributy objektu (ne atributy jeho sousedů). Tento strom má sice velmi nízkou chybovost (méně než 1%), ale nezískáme téměř žádnou znalost o prostorových vlastnostech dat.
Po odebrání atributů(rozloha, 1), (zamestnancu, 1), (dokon_bytu, 1) a ponechání pouze vlastních atributů (obci, 0) a (mzda, 0) získáme strom, jehož chybovost je 12%. Počet atributů sousedů je v něm opět omezen, ale ne tolik jako v původním stromu se všemi atributy. Tento strom je poměrně rozsáhlý, proto zde uvedeme pouze malou část:
(nezam_1_misto, 1) <= 33.1 :
| (obci, 0) <= 71 :
| | (nezam_1_misto, 1) <= 19.7 :
| | | (obci, 0) <= 39 :
| | | | (obci, 0) <= 38 : 2 (6.0/2.3)
| | | | (obci, 0) > 38 : 1 (3.0/1.1)
...
Závěr
Klasifikace podle atributů sousedních objektů nevykazuje takovou přesnost jako klasifikace podle vlastních atributů objektu. Při vhodné kombinaci s atributy objektu však získáme strom s dobrou přesností, aniž bychom ztratili prostorovou informaci.
Uvedli jsme algoritmus pro klasifikaci prostorových dat. Implementovali jsme tento algoritmus za použití objektově relační databáze Postgres a systému pro tvorbu rozhodovacích stromů C4.5. Touto metodou jsme získali obecná pravidla pro odhad nezaměstnanosti v okresech České republiky.
Odkazy
[1] Český statistický úřad: http://www.czso.cz/
[2] PostgreSQL: http://www.postgresql.org/
[3] Ester M., Kriegel H. P., Sander J.: Spatial Data Mining: A Database Approach. Proc. of the Fifth Int. Symposium on Large Spatial Databases (SSD '97), Berlin, Germany, Lecture Notes in Computer Science, Springer, 1997.
[4] Fanta P.: Prostorové SQL pro Postgres, semestrální projekt, Fakulta informatiky, Masarykova univerzita, Brno.
[5] Fanta P., Kuba P.: Úpravy systému C4.5, semestrální projekt, Fakulta informatiky, Masarykova univerzita, Brno.
[6] Mitchell, T.M.: Machine Learning. McGraw Hill, New York, 1997.
[7] Popelínský L.: Approaches to Spatial Data Mining. Sborník konference GIS Ostrava 99, Ostrava 1999.
[8] Quinlan, J. R.: C4.5: Programs for Machine Learning. Morgan Kaufmann Publ. 1992.