Dr.Ing. Jiří Horák - Dr.Ing. Bronislava Horáková
Institut geoinformatiky
VŠB - Technická univerzita Ostrava
tř. 17. listopadu
708 33 Ostrava - Poruba
E - mail: jiri.horak@vsb.cz, bronislava.horakova@vsb.cz
Socioeconomical data are frequently represented by areals of administrative units. Processing and visualisation of such data are negatively influenced by differences in size and shape of territorial units, small data quantity. These aspects produce high fluctuations in studied phenomena, which don't mirror natural variability, but only differences in mapping units. Smoothing of data, which enable understanding of spatial pattern and trend, represents one of the possibilities for improving the situation. The paper give a review of selected methods of spatial smoothing including Bayes smoothing and present results of their applications for examples of processing data on a municipality level.
Socioekonomická data jsou často prezentována prostřednictvím areálů administrativních jednotek. Jejich zpracování a vizualizace je však negativně ovlivněno rozdíly ve velikosti a tvaru administrativních jednotek, malou velikosti datové základny a tedy značnými výkyvy sledovaného jevu, který neodráží variabilitu sledovaného jevu, ale právě rozdíly v mapovaných jednotkách. Jednou z možností zlepšení studia příslušného jevu je vyhlazení dat s cílem zdůraznění prostorového vzoru, trendu. Příspěvek podává přehled vybraných metod prostorového vyhlazení včetně Bayesova vyhlazení a dokumentuje jejich výsledky na příkladech studia dat na úrovni obcí.
Pro reprezentaci socioekonomických dat se velmi často používají areály. Řada statistických údajů je primárně vztahována k areálům, protože jsou na základě agregace publikovány za určitá území či sídelní jednotky. Mohou to být administrativní jednotky, ale i jinak vymezené areály (v ČR např. základní sídelní jednotky, jinde censovní obvody či poštovní okrsky). Z administrativních jednotek se používají především obce ve svých správních hranicích, okresy (od 1.1.2003 zřejmě zaujme jejich místo území obcí s rozšířenou působností) a kraje (na úrovni NUTS2 i NUTS3), ke kterým se evidují statistické údaje publikované ČSÚ i dalšími institucemi, méně např. katastrální území (statistika typu půdy, vlastnictví apod.)
Socioekonomická data využívají běžně k lokalizaci geokódy. Vzhledem k charakteru dat jsou to zpravidla identifikátory geografických, často administrativních jednotek. Používání těchto jednotek zabezpečuje v řadě případů nezbytnou agregaci vstupních dat, ale také zjednodušuje lokalizaci údajů (digitální vymezení administrativních hranic územních jednotek bývá jedním ze základních digitálních mapových podkladů státu, proto nebývají problémy s jejich získáním ani s aktualizací) a v neposlední řadě poskytuje společný základ pro řadu zjišťovaných údajů (poskytovaných orgány veřejné správy či statistickým úřadem).
V případě trhu práce je územní diferenciace faktorů vyjadřována v závislosti na měřítku pozorování pomocí hranic krajů, okresů, mikroregionů a obcí. Analýzy v mikroměřítku využívají jako agregační jednotky zpravidla obce, ojediněle i části obcí (Horák et al. 2000).
Měřítko ovlivňuje i přesnost sledování jevů. Zatímco v mikroměřítku může způsobovat náhodná chyba či odchylka problémy (vychýlení z pozorovaného trendu), na úrovni regionů již dochází k průměrování a vyrovnávání odchylek, takže výsledek je méně zatížen náhodnými chybami (analogie s velikostí výběrového vzorku). Proto se zvláště v mikroměřítku uplatňují více postupy vyhlazování či alespoň metody robustních odhadů (např. bootstrap).
Na druhou stranu ale používané administrativní jednotky jsou zdrojem řady omezení a problémů. Z hlediska vymezení jednotek můžeme určit 3 základní skupiny problémů (Horák 2002):
A. Nevyrovnanost jednotek
B. Časová nestabilita jednotek
C. Vnitřní nehomogenita jednotek
Používané administrativní jednotky nejsou v řadě případů dostatečně ekvivalentní. Významné rozdíly ve velikosti obcí měřené např. počtem obyvatel značně ovlivňují výsledek zpracování. Tvar a velikost administrativních jednotek relativně málo koinciduje s rozložením zkoumaného jevu v území a to vede k nežádoucímu apriornímu ovlivňování vzhledu kartogramu. Rozdíly ve velikosti výměry obcí způsobují zvýraznění role velkých obcí v okrese či regionu. Přitom může jít o horskou obec s velkou výměrou, ale malým počtem obyvatel či pracovní síly. Administrativní jednotky mají tendenci přetrvávat v obraze a dominovat následným analýzám (Bracken 1994). Výsledný vjem, vzor, je tedy značně ovlivněn nevyrovnaností prostorové reprezentace.
Tvarem územních jednotek, jejich parametry, fragmentací a vztahem k možnosti transformace do pravidelných jednotek se zabývá Bachi (1999).
Problémy s nehomogenitou území je možné doložit na příkladu okresu Frýdek-Místek.
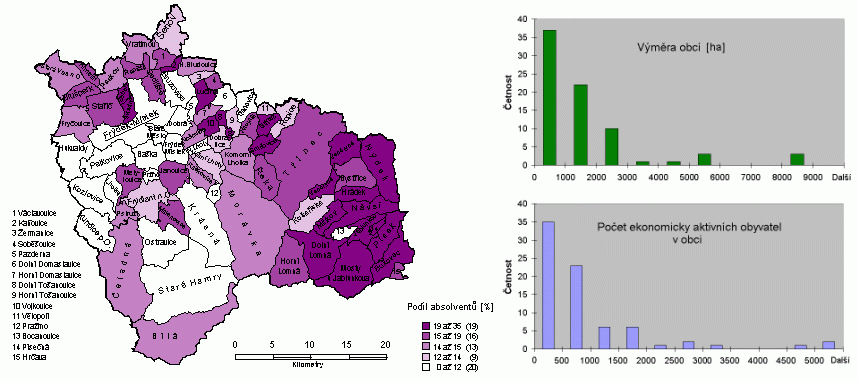
Na obr. 1 je možné dokumentovat velké rozdíly ve výměře obcí, kde na území Beskyd mají obce výrazně větší rozlohu. Podobné výrazné rozdíly existují i v počtu ekonomicky aktivních obyvatel. V obou histogramů je exponenciální tvar křivky narušen několika obcemi s výrazně vyšší výměrou či počtem obyvatel.
Obr. 1 Kartogram podílu absolventů z celkového počtu uchazečů o zaměstnání v obcích okresu Frýdek-Místek (31.12.2001) a histogramy výměry obcí a počtu ekonomicky aktivních obyvatel obce (převzato z Horák 2002)
Zvláštním důsledkem neekvivalence jednotek mohou být systematické chyby, které pramení z rozdílů (třeba i malých) v metodice zjišťování příslušného jevu. Vedle zdravotnických a epidemiologických studií, kde na problém upozorňuje English (1996), se tato situace projevuje i u dalších dat. Zvláště u socioekonomických dat může docházet k metodickým rozdílům mezi jednotlivými administrativními jednotkami, které jsou spravovány jinde situovanými úřady. Přes požadavek metodické jednoty, který bývá na úřadech stejného typu vyžadován, dochází k drobným odlišnostem např. ve vybavení úřadů, při interpretaci metodických pokynů, v realizaci jednotlivých činností. Oblast trhu práce a činnost úřadů práce tento předpoklad potvrzuje - např. v oblasti evidence firem (které firmy jsou monitorovány, jak často, zda existuje spolupráce s jinými veřejnými institucemi při verifikaci a doplňování dat).
Negativní vliv na používání administrativních jednotek má nestabilita administrativního členění území. Dochází ke změnám hranic stávajících jednotek nebo k jejich rozdělování a slučování. V takovém případě je nutné údaje zpracovat podle známých poměrů, což v případě disagregace (zde odhad hodnot pro dílčí jednotky) vede ke zvýšení neurčitosti dat.
Nestabilita administrativního členění je v ČR v poslední době značná, v devadesátých let docházelo k významných pohybům na úrovni obcí, od 1.1.2003 zanikají okresy a začínají pracovat pověřené obce nového typu.
Nestabilita územního vymezení administrativních jednotek vede často i k potřebě modifikovat tvar areálů těchto jednotek, resp. distribuovat hodnoty z jednoho areálu do druhého. Tuto úlohu označujeme jako problém areálové interpolace neboli problém MAUP (Modifiable Area Unit Problem). Problém se již dotýká zpracování dat a ne jejich vymezení.
Cílem je distribuovat hodnoty ze zdrojových areálů do cílového areálu při jejich překrytí. Podstatný je způsob kombinace dílčích hodnot (přenesených ze zdrojových areálů) do výsledné hodnoty pro cílový areál. Běžně se používají vážené aritmetické průměry a váha se určuje v závislosti na tom, zda jde o veličinu absolutní nebo relativní. Snadné řešení představuje vážení pomocí ploch areálů (areal weighting). Metodu popisuje např. Flowerdew, Green (1994), Horák (1996).
Sten (1997) popisuje v podstatě dasymetrickou úpravu této metody, využívající pro vážení i rozmístění osídlení (vrstva osídlení).
Složitější postupy využívají pro modelování distribuce sledované veličiny v ploše zpravidla Poissonovo rozdělení. Regresní modely založené na předpokladu Poissonovy distribuce pro výskyt sledované veličiny se aplikují buď přímo nebo pomocí iteračního postupu označovaného jako EM algoritmus (Flowerdew, Green 1994), používaného pro absolutní hodnoty.
Je třeba si uvědomit, že správní (tj. administrativní) hranice zpravidla rozdělují beze zbytku celé zkoumané území. Jejich parametry (velikost, tvar, těžiště) neodpovídají parametrům urbanizovaného území, které je mnohem menší a málokdy odpovídá administrativní jednotce tvarem či polohou těžiště.
Významnou částí urbanizovaného území je zastavěné území, u kterého můžeme uvést pro představu podíl z celkové výměry obcí. Zastavěné území činilo v roce 2000 v České republice asi 1,7 % z celkové rozlohy. Konkrétně v Moravskoslezském kraji tvoří zastavěné území v obcích od 0,2% pro obce Staré Hamry a Bílá v Beskydech do 10% pro Ostravu, v průměru 2,1% (zdroj dat Český ústav zeměměřický a katastrální, 31.12.2000).
Z tohoto pohledu by bylo pro řadu úloh vhodnější využít geografických jednotek typu urbanizované plochy. Vymezení takových jednotek ale není objektivní, nemá oporu v legislativních normách (vyhláška, zákon) a je tedy sporné, kudy vést hranici urbanizovaného území. Navíc při dotyku urbanizovaných území dvou obcí se opět musí využít administrativní hranice, takže dělení není konzistentní.
Vnitřní nehomogenitu jednotek obecně můžeme řešit rozdělením území na menší, homogenní jednotky. To je v řadě případů doprovázeno specifickým problémem distribuce hodnot známých za větší (typicky administrativní) jednotky na jednotky menší. Vedle distribuce hodnot lze hovořit i o disagregaci jako opaku agregace.
Distribuci hodnot v subjednotkách neznáme a nelze ji stanovit náhodně. Je však možné využít informace o distribuci jiné veličiny ve sledovaném území, která má vztah k mapovanému jevu. Tento vztah často není formálně popsán, ale může být založen na jisté příčinné souvislosti nebo dokonce jen na statisticky prokázaném korelačním vztahu.
Typickým příkladem je třeba počet obyvatel v obci, který se nevztahuje rovnoměrně k celému území obce ve správních hranicích, ale jen k urbanizovaným částem. Máme-li k dispozici mapu pokryvu území, lze usuzovat, že největší procento obyvatelstva bude situováno v zastavěných oblastech, malé množství obyvatelstva v lesních či polních oblastech (samoty apod.) a žádní obyvatelé nebudou osídlovat území označené jako vodní plocha. Podle zastoupení obyvatelstva se pak rozpočítá celková hodnota mezi jednotlivé subjednotky. Samozřejmostí je dodržení konzistence dat, tedy omezení, že součet hodnot v subjednotkách se rovná celkové hodnotě.
Tyto metody patří do skupiny označované jako dasymetrické metody, popsaný způsob označuje Kaňok (1992) jako analýzu kartogramickou a popisuje ho i např. Ivanička (1983).
Vedle deterministického určení podílu hodnoty příslušející subjednotkám je možné využít pravděpodobnostního přístupu. Lze například odhadnout pravděpodobnost distribuce sledovaného jevu v daných subjednotkách (určení nejenom střední hodnoty, ale i variability či typu distribuce) a následně použít simulaci typu metody Monte Carlo. Po dostatečném počtu simulací rozdělení hodnot v území by bylo možné ocenit i spolehlivost takového odhadu.
Takový postup se označuje jako mikrosimulace a popisuje ho např. Birkin et al. (1996).
Uvedená simulace má nedostatečný prostorový aspekt, protože pro každý typ subjednotky předpokládá stejnou distribuci hodnot, bez ohledu na jejich geografickou polohu a sousedství. Přitom lze očekávat, že existuje jistá prostorová kontinuita mezi nimi. V uvedeném příkladu distribuce obyvatel je možné předpokládat, že např. typ subjednotky "les" bude mít různou pravděpodobnost osídlení v rámci sledovaného území - nejvyšší pravděpodobnost lze očekávat v blízkosti (v sousedství) zastavěných území.
Další rozšíření simulačního modelu by tedy mělo zohledňovat prostorovou situaci (např. jistou interpolací či vyhlazením z okolí). Uvedený postup je obtížné zobecnit (vyjádřit exaktní postup vážení), protože velký vliv na rozhodnutí má, zda a v jaké formě zahrnout vliv okolí, způsob vymezení subjednotek (způsob klasifikace, měřítko), typ sledovaného jevu a jeho způsob zjišťování atd.
V nedávné době se již objevily i postupy umožňující využít místo simulací sebepodobnosti a fraktálové geometrie pro modelování výskytu sledovaného jevu uvnitř mapované jednotky. Prostorová kontinuita pole může být vhodně vyjádřena právě sebepodobností.
Využívání administrativních jednotek tedy vede k řadě obtíží. Jako alternativa se nabízí používání geometrických hranic. Umělé jednotky, které jsou geometricky vymezené, mohou být stejně velké a nemusejí podléhat žádným administrativním změnám.
Při vyhodnocování je třeba vzít v úvahu měřítko, protože řada jevů (resp. jejich textura) je snáze pozorovatelná v globálnější pohledu než lokálním měřítku. Z hlediska tvaru buněk se nejvíce používají čtverce a šestiúhelníky.
K ilustraci můžeme použít příklad z oblasti studia nezaměstnanosti ve městě (Glacová, Horák 2002). K agregaci byly použity čtverce o velikosti 600x600m, 300x300m a 200x200m, vlastní vyhodnocování situace využívalo především posledně uvedenou síť (Horáková et al. 2002a, 2002b). Výstupní data po zpracování jsou tedy tvořena počty bydlících v jednotlivých čtvercích - celkem a zařazených do jednotlivých skupin dle věku, pohlaví, počet uchazečů o zaměstnání ve výše uvedené struktuře a počet neplatičů nájemného (obr. 2).
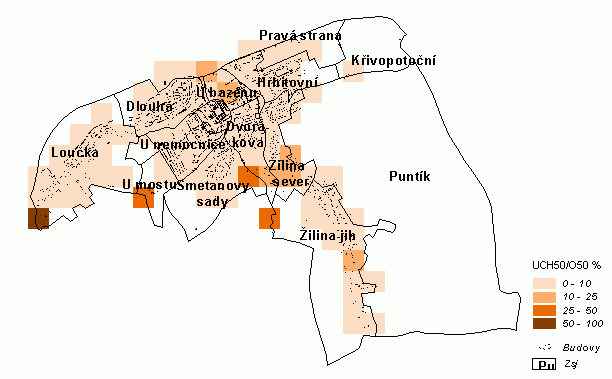
Obr. 2 Specifická míra nezaměstnanosti starších nad 50 let v Novém Jičíně (buňky 300x300 m)
Při práci se socioekonomickými údaji jsme často konfrontováni se značnou variabilitou zkoumaného jevu. Pozorovaná sada dat může vykazovat v území značné rozdíly a někdy lze jen obtížně nalézt generelní průběh hodnot (trend), odhalit a interpretovat texturu (vzor), která se projevuje.
Cílem vyhlazování areálových dat je tedy odhalení a zvýraznění efektu 1.řádu, tedy změn ve střední hodnotě (označované zpravidla jako trend), které se ve sledovaném území projevují.
Předpokládejme, že pozorované atributy Z(si) představují realizaci proměnné veličiny Z v jednotlivých areálech si. Veličina Z je složena v nejjednodušším případu z pravidelné složky, která závisí na poloze v území, a náhodné složky, která může ale nemusí záviset na poloze v prostoru. Při vyhlazování dat se tedy potlačuje náhodná složka a posiluje zobrazení pravidelné složky.
Vyhlazení má smysl v případě, že existuje jistá prostorová kontinuita hodnot. Pokud předpokládáme, že náhodná složka nezávisí výrazně na poloze v prostoru, můžeme usuzovat, že náhodné variace se v blízkém okolí mohou vzájemně eliminovat a že tedy můžeme náhodný vliv na hodnoty Z potlačit nějakou formou váženého průměrování. Zpravidla se přitom využívá jednoduchého lineárního modelu.
Prostorové klouzavé průměry pracující ve 2D nahrazují původní hodnoty pro každý areál váženým aritmetickým průměrem hodnot v sousedních areálech.
Na rozdíl od jednorozměrného případu klouzavých aritmetických průměrů se používá především přímých sousedů a jen u některých variant také vzdálenějších "sousedů", tj. areálů bez společné hranice. Přidělované váhy jsou také jednodušší a bez přímého vztahu k velikosti areálů a z toho vyplývající nepřesnosti v lokalizaci zjištěných hodnot. Základní vztah pro výpočet nové hodnoty areálu je:
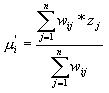
kde
zj původní hodnoty v sousedních areálech
wij váha hodnoty v sousedním areálu j z místa i
j index vymezující sousední areály
![]() vyhlazená hodnota z v areálu i
vyhlazená hodnota z v areálu i
Alternativou může být pro výpočet poměru i sumace čitatele a jmenovatele a následně výpočet podle vztahu:
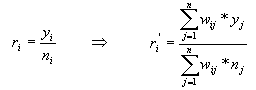
Protože váhy wij nejsou standardizovány do rozsahu <0,1>, musí se provést standardizace jejich součtem ve jmenovateli zlomku.
Existuje celá řada variant této metody lišící se způsobem vymezení sousedství a nastavením vah wij. Jejich základní přehled uvádí Bailey, Gatrell (1995). Sousedství a hodnoty vah doporučuje popisovat pomocí matice vah W o rozměru n x n, kde n je počet areálů. Váha wij mezi dvěma areály může být vyjádřena jako:
1) | wij= 1 | Pokud těžiště areálu j je jedním z k nejbližších těžišť vůči areálu i |
wij= 0 | v ostatních případech | |
2) | wij= 1 | Pokud těžiště areálu j je do jisté vzdálenosti |
wij= 0 | v ostatních případech | |
3) | wij= | Pokud je vzdálenost dij mezi těžištěm areálu i a j menší než jistá vzdálenost |
wij= 0 | v ostatních případech | |
4) | wij= 1 | Pokud areál j sdílí společnou hranici s areálem i |
wij= 0 | v ostatních případech | |
5) | wij= lij/li | kde lij je délka společné hranice mezi areálem i a j; resp. li je obvod areálu i |
Některé způsoby výpočtu wij obsahují parametry (k, ![]() ,
, ![]() ), které je možné optimalizovat.
), které je možné optimalizovat.
Metoda byla vyzkoušena pro míru nezaměstnanosti v obcích okresu Frýdek-Místek k 31.12.2001, která nejeví příliš zřetelný trend v primární podobě (obr. 3). Pro výpočet vah bylo použito jednoduché 4.varianty, tedy topologického způsobu, kdy je vyhlazení prováděno na základě hodnot v sousedních areálech (obr. 4). S ohledem na zkoumání míry nezaměstnanosti, tedy poměru, byla dále použita modifikace se sumací čitatele a jmenovatele v sousedních obcích a až následný výpočet míry nezaměstnanosti (obr. 5).
Trend u topologického vyhlazení je v obou případech již zřetelný (očekávaná vlastnost topologického vyhlazení), nicméně byly získány dva odlišné vzorky, což vyžaduje vyzkoušení vyhlazení i dalšími metodami, aby se nalezla vhodná varianta řešení. Je třeba říci, že pozorovaná situace není zcela typická, protože okresní město (s velkým počtem obyvatel) má vysokou míru nezaměstnanosti a skládá se ze 2 nespojitých polygonů, což vede k abnormálnímu zvýšení počtu sousedů a tedy dalšímu zdůraznění vlivu tohoto areálu v území (viz především obr. 5).
Uvedených 5 variant neposkytuje vyčerpávající přehled možností vyjádření vah (vazeb) mezi areály, lze využít i různých kombinací výpočtu např. délka společné hranice a vzdálenost mezi těžišti. Vhodnou formou zobecnění vzdálenosti bude i využití cestovního času mezi areály.
Jak uvádí Bailey, Gatrell (1995), pro některé metody se používají matice vah pro popis vazeb vyšších řádů, nejenom pro nejbližší sousedství. Tímto způsobem lze definovat tzv. prostorové kroky (spatial lags), tedy popisovat váhy pro 2.nejbližší sousedství, 3.nejbližší sousedství atd. Tento postup můžeme použít i pro popis kontinuity zkoumaného fenoménu v oblasti. Zde se však již nabízí alternativa ve formě transformace areálových měření na bodová, ať už v nepravidelné síti (využití těžišť areálů nebo center osídlení) nebo v pravidelné síti, a následném uplatnění geostatistických metod. Jinou možností je po provedené transformaci využití jádrového vyhlazení.
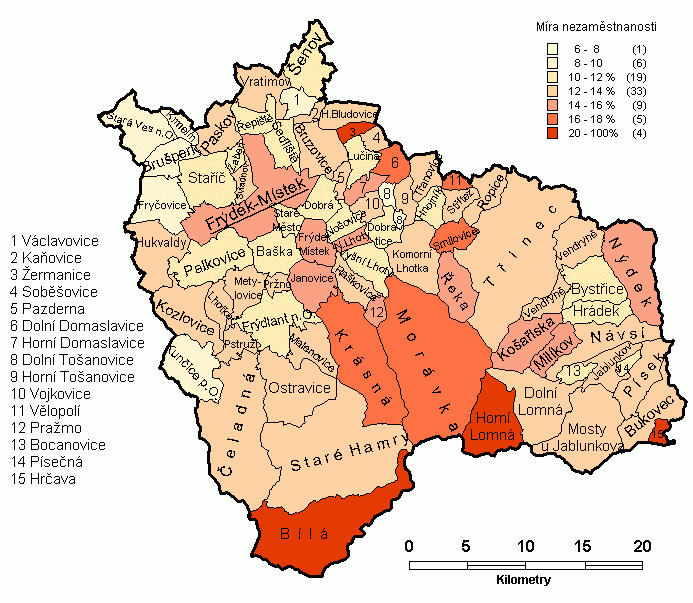
Obr. 3 Míra nezaměstnanosti v obcích okresu Frýdek-Místek k 31.12.2001
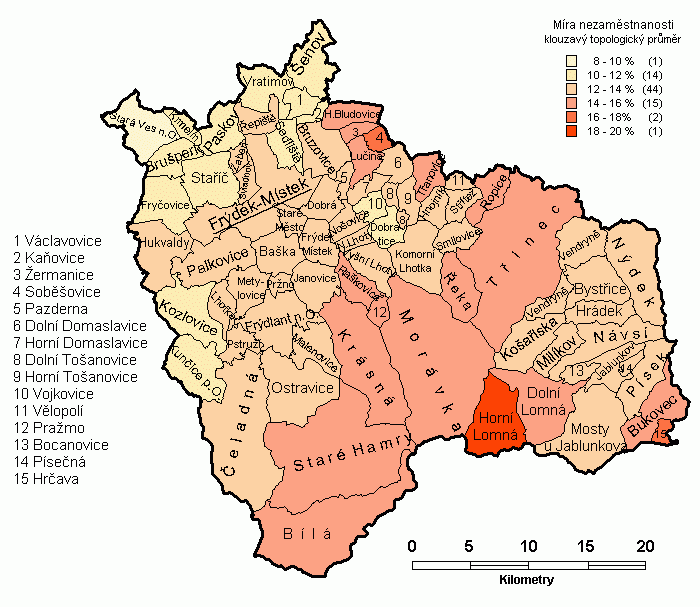
Obr. 4 Topologicky vyhlazená míra nezaměstnanosti v obcích okresu Frýdek-Místek k 31.12.2001
Za jednu z nevýhod metody považujeme skutečnost, že jednotlivé areály mají všechny stejnou váhu, přitom mají rozdílné plochy (což ovšem některé varianty výpočtu wij nepřímo zohledňují), ale v případě socioekonomických dat především rozdílnou velikost datové základny. Např. při vyhlazování míry nezaměstnanosti musí být zohledněna různá velikost populace, tj. počet ekonomicky aktivních obyvatel.
Další komplikací je výskyt nespojitých areálů (např. některé obce mají nespojité území). V tom případě výčet sousedních areálů značně narůstá a tyto areály příliš silně ovlivňují své okolí.
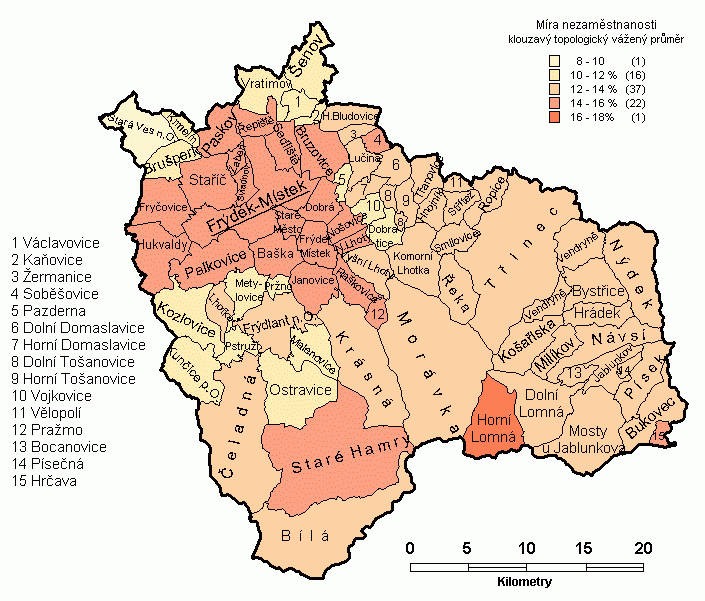
Obr. 5 Vážený aritmetický průměr míry nezaměstnanosti ze sousedních obcí okresu Frýdek-Místek k 31.12.2001
Bayesovo vyhlazení využívá Bayesova přístupu k výpočtu pravděpodobnosti, kde se apriorní nepodmíněná pravděpodobnost pro sledovaný jev kombinuje se zjištěnou (měřenou) pravděpodobností a vzniká nová, posteriorní pravděpodobnost pro sledovaný jev.
Bayesův přístup je možno při vyhlazování využít tak, že získaná data kombinujeme s vhodným apriorním odhadem, kterým může být např. střední hodnota sledovaného jevu pro celé území. Areály, kde je nízká věrohodnost získaných dat, protože je zde malá datová základna, jsou více regulovány (tj. vyhlazovány) než areály s velkou datovou základnou a tedy vyšší věrohodností získaných dat.
Popis obecného vztahu Bayesova odhadu je možné nalézt v Bailey, Gatrell (1995) nebo Horák (2002).
Parametry potřebné pro výpočet se odvozují metodou maximální věrohodnosti. Lze však použít určitá zjednodušení, kdy se tyto parametry odhadují na základě momentových charakteristik. Výsledný vztah je pak možno vyjádřit jako:
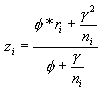
kde ![]() je střední hodnota a
je střední hodnota a ![]() je rozptyl sledovaného jevu, které lze při zjednodušení určit pomocí momentových charakteristik jako:
je rozptyl sledovaného jevu, které lze při zjednodušení určit pomocí momentových charakteristik jako:
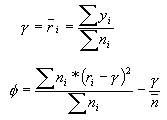
n s pruhem je průměrná populace v území.
Vzorec platí, pokud je ![]() >0, jinak
>0, jinak ![]() =0.
=0.
Výsledek pro míru nezaměstnanosti v okrese Frýdek-Místek je na obr.6.
Obr. 6 Bayesovo vyhlazení míry nezaměstnanosti v obcích okresu Frýdek-Místek k 31.12.2001
V uvedené základní podobě používá Bayesovo vyhlazení konstantní průměr a rozptyl v celé území. Je zřejmé, že tento předpoklad nemusí vždy vyhovovat a že v řadě případů bude vhodné předpokládat existenci trendu a změn variability v území. Metodu je možné snadno modifikovat nahrazením globálního průměru a rozptylu za statistické charakteristiky sousedství - použije se hodnot sousedních areálů k výpočtu průměru a rozptylu. Jde tedy o adaptivní Bayesovo vyhlazení, které bude vyhlazovat s přihlédnutím k lokálními vývoji hodnot. Pojem sousedství je zde opět použit v obecné rovině - k vymezení sousedství můžeme použít topologie a/nebo vzdálenosti (zpravidla těžišť areálů). Můžeme tak dosáhnout zajímavých výsledků jako je např. vyhlazená míra nezaměstnanosti s ohledem na spádovost území vyjádřenou např. dopravními časy mezi obcemi.
Výsledek adaptivního Bayesova vyhlazení pro studovanou situaci s využitím sousedství pro výpočet lokálních průměrů je na obr. 7. Je evidentní, že je míra nezaměstnanosti příliš snížena a že je využití nejbližších sousedů (zvláště pro velmi nehomogenní území) značně omezené. Ukazuje se, že je potřebné upravit metody tak, aby se ovlivňující okolí stanovovalo na základě studia autokorelace jevu v území.
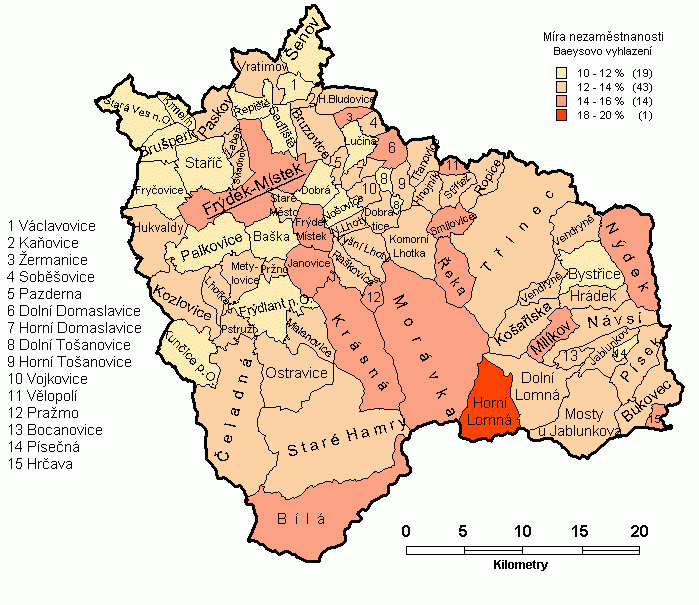
Obr. 7 Adaptivní Bayesovo vyhlazení míry nezaměstnanosti v obcích okresu Frýdek-Místek k 31.12.2001
Zpracování a vizualizace socioekonomických dat je silně ovlivněno použitou agregační jednotkou a charakteristikou použitých geografických jednotek. Hlavní problémy při používání administrativních jednotek lze spatřovat v nevyrovnanosti jednotek (rozdíly ve velikosti území, velikosti sledované populace apod.), dále v časové nestabilitě (změny administrativního uspořádání) a rovněž ve vnitřní nehomogenitě (distribuce populace uvnitř administrativní jednotky bývá značně nerovnoměrná). Jednou z možností eliminace problémů je použití geometrických jednotek k agregaci.
Při vyhodnocení rozložení sledovaného jevu v území není často jednoduché postihnout trend rozložení jevu v území. Především v těchto situacích lze uplatnit různé varianty vyhlazení např. prostorového klouzavého průměru.
Za velmi slibnou techniku považujeme Bayesovské vyhlazení, které umožňuje vyhlazovat hodnoty s ohledem na celkový průměr a potlačit tak jevy, které se objevují v důsledku náhodných variací u hodnot, zjištěných pro místa s malou populací, tj. s malou datovou základnou.
Metodika výpočtu je dokumentována na příkladech studia nezaměstnanosti z okresu Frýdek-Místek a města Nový Jičín.
Příspěvek vznikl na základě finanční podpory Grantové agentury České republiky v rámci projektu GA 402/02/0855 "Modelování trhu práce s využitím geoinformačních technologií". Děkujeme pracovníkům Úřadu práce Frýdek-Místek, Úřadu práce Nový Jičín a Městského úřadu Nový Jičín za spolupráci a poskytnutá data.