Tomáš Buk, Petr Kuba, Luboš Popelínský
Laboratoř vyhledávání znalostí
Fakulta Informatiky MU, Brno
Botanická 68a, 602 00 Brno
E - mail: xbuk@fi.muni.cz, xkuba@fi.muni.cz, popel@fi.muni.cz
GRR is a system for mining in geographical information system GRASS. It is composed of graphical user interface, interface for communication with R system and for communication with geographical information system. Discovered knowledge is expressed in language PMML. The system allows visualization of the knowledge. GRASS (Geographical Resources Analysis Support System) is a geographical information system developed since 1982. It is open-source free software (released under GNU General Public Licence). It operates on operating systems UNIX (on various platforms), but version for Windows NT/2000/XP (with system cygwin) exists as well. GRASS can be used for data management, spatial modeling, image processing and data virtualization of many formats. It can work with both raster and vector data. R is a system for data analysis and graphical presentation of results also released under GNU Licence. Nowadays, versions of R system exist for UNIX, Windows 9x/NT/2000 and Mac OS. The system includes programming language with compiler and libraries. R provides wide range of statistical methods and machine learning algorithms, e.g. classification, clustering, linear and nonlinear modelling, association rules etc. We extended R system with inductive logic programming methods which allow generating classification rules in first order logic. Moreover, method for mining frequent patterns was added. This method allows generation of patterns which can describe more complex structures than e.g. data stored in simple relational table. PMML, Predictive Modeling Markup Language, is a proposed standard for data mining results representation. It is supported in both noncommercial systems for knowledge discovery in databases (Knowledge Discovery Support Engines, KDDSE) and commercial firms such as IBM, Oracle, SAS and SPSS. The paper describes the structure of GRR system and mention its methods for preprocessing and data mining. User can choose one of predefined tasks or create its own task. The example of work with the system is presented.
GRR je systém pro dolování v geografickém informačním systému GRASS. Skládá se z grafického uživatelského rozhraní, rozhraní pro komunikaci se systémem R a pro komunikaci s vlastním geografickým informačním systémem. Výsledné znalosti jsou vyjádřeny v jazyku PMML, standardu pro reprezentaci výsledků data mining, který je podporován jak nekomerčními systémy pro vyhledávání znalostí v databázích tak velkými firmami. Systém umožňuje vizualizaci znalostí. Systém R jsme rozšířili o metody induktivního logického programování, pomocí kterých je možné generovat klasifikační pravidla v logice prvního řádu a dolovat časté vzory a asociační pravidla. Uživatel může zvolit některou z předdefinovaných úloh nebo vytvořit svou vlastní. Práce se systémem je demonstrována na příkladu.
Od počátku 90. let vznikla řada nástrojů pro usnadnění dolování (dobývání) znalostí z geografických dat. GeoMiner http://db.cs.sfu.ca/GeoMiner/ umožňuje vyhledávat různé druhy znalostí v prostorovém databázovém serveru. Jeho základem je systém DBMiner, který slouží pro vyhledávání znalostí v relačních databázích. Systém Descartes http://allanon.gmd.de/and/descartes.html slouží k vizualizaci prostorových dat v interaktivních tematických mapách. K tomuto účelu nabízí dva základní nástroje, automatickou vizualizaci (prezentaci dat na mapách) a interaktivní manipulaci s vytvořenými mapami. Dalším systémem je GWiM [Popel98] který využívá induktivní logické programování [ILP94] pro vyhledávání znalostí v prostorových datech. Je založený na ILP systému WiM [Popel02] a obsahuje dotazovací jazyk pro vyhledávání znalostí. V článku [Kuba00] je navržen jazyk pro vyhledávání znalostí v prostorových datech, který sjednocuje přístup k několika programům pro dolování v datech. Pro reprezentaci prostorové informace obsažené v datech využívá grafy sousednosti a cesty v těchto grafech. Jazyk umožňuje dolovat klasifikační pravidla, charakteristická pravidla a diskriminační pravidla. Z nejnovějších uveďme dva systémy, SPIN! a INGENS. Cílem evropského projekt SPIN! http://www.ccg.leeds.ac.uk/spin/ je vytvoření systému pro dolování v geografických datech pro účely statistických úřadů zúčastněných zemí. Integruje v sobě již zmíněný systém Descartes spolu s obecným dolovacím nástrojem Kepler. INGENS [Maler02] slouží pro interpretaci map s využítím metod strojového učení. Interpreter dotazů dovoluje uživateli formulovat dotazy v SDMOQL, nadstavbě objektově orientovaného dotazovacího jazyka OQL http://www.odmg.org . Geografická data jsou uložena v DBMS ObjectStore.
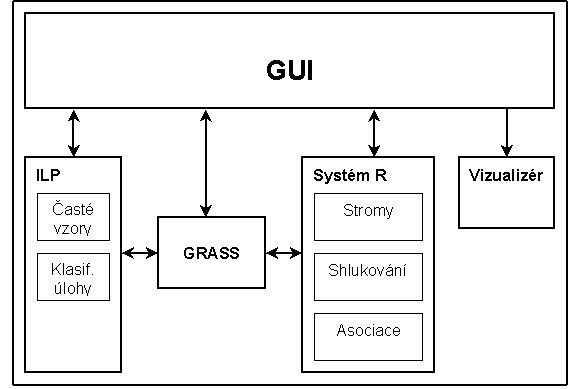
Cílem našeho projektu bylo vytvoření systému pro dolování v geografických datech, který by byl snadno dostupný pro běžné uživatele, snadno rozšiřitelný a co nejméně závislý na použitém geografickém informačním systému. GRR je systém pro dolování v geografickém informačním systému GRASS. Skládá se z grafického uživatelského rozhraní, rozhraní pro komunikaci se systémem R a pro komunikaci s vlastním geografickým informačním systémem. Výsledné znalosti jsou vyjádřeny v jazyku PMML. Systém umožňuje jejich vizualizaci. Strukturu systému znázorňuje obr. 1.
Stručný popis systému a jeho implementace jsou obsahem následujících dvou odstavců. Po nich následuje popis jednotlivých částí systému GRR.
Systém GRR je nástroj pro dolování v systému GRASS. Uživatel komunikuje s tímto systémem pomocí grafického uživatelského rozhraní. GRR, jak již bylo zmíněno, zahrnuje rozhraní pro komunikaci se systémem R i se samotným geografickým informačním systémem. Díky tomu je možné aplikovat na geografická data metody implementované v systému R.
Obr. 1 Struktura systému GRR
V současné verzi systému GRR jsou k dispozici následující metody předzpracování a metody dolování:
Metody předzpracování
Metody dolování
Dále GRR díky rozhraní mezi R a GRASSem umožňuje vytvářet na základě výsledků výše zmíněných metod v GRASSu nové datové vrstvy. Příklad takové vrstvy je uveden na závěr tohoto textu.
Systém GRR je implementován v jazyku Perl (verze 5.6.1), přičemž pro tvorbu grafického uživatelského rozhraní bylo využito Tk (verze 8.0) (toolkit pro vytváření 'okennich' aplikaci). GRR byl vytvořen a testován v operačním systému Linux RedHat 7.2. GRR byl testován s geografickým systémem GRASS verze 5.0.0 a systémem R verze 1.6.1. Pro komunikaci mezi systémem GRASS a R byl použit v systému R přídavný modul GRASS (verze 0.1-11) Rogera Bivanda. Jako vizualizátor byl použit PMML vizualizer [Wetts02] implementovaný v jazyce java.
GRASS (http://grass.itc.it/) (zkr. Geographical Resources Analysis Support System) je geografický informační systém vyvíjený od roku 1982. Jde o tzv. "open-source" free software (v ramci projektu GNU). GRASS v současnosti pracuje pod operačními systémy UNIX (na různých platformách) s grafickým uživatelským rozhraním X-Windows, existuje však i verze pro Windows NT/2000/XP (s použitím systému cygwin). Systém GRASS lze využívat např. pro tzv. "data management", prostorové modelováni, zpracování obrazu a pro virtualizaci dat mnoha různých formátů. Jde o rastrově-vektorový GIS.
R (http://www.r-project.org/) je systém pro analýzu dat a grafickou prezentaci výsledku. Jde opět o volně šířitelný software v rámci projektu GNU. V současné době existují verze systému R pro operační systémy UNIX, Windows 9x/NT/2000 a Mac OS. Součástí systému je programovací jazyk s překladačem a systém knihoven. Systém R poskytuje širokou škálu metod předzpracování dat, statistických technik a algoritmů strojového učení, např. klasifikace, shlukováni, lineární a nelineární modelováni, asociační pravidla apod. Umožňuje též výsledky vizualizovat.
Systém GRR také zahrnuje rozhraní pro komunikaci s ILP systémy [ILP94], čímž umožňuje uživateli aplikovat na data z GRASSu metody ILP, např. metody pro generování klasifikačních pravidel v logice prvého řádu. Dále je přidána metoda pro dolování častých vzorů [Blaťák02], která dovoluje generovat vzory popisující složitější struktury, než jaké mohou být uloženy např. v jednoduché relační tabulce.
Výsledky, získané aplikací výše uvedených metod, které GRR nabízí, jsou generovány v jazyku PMML (http://www.dmg.org/pmml-v1-1.htm).PMML, Predictive Modeling Markup Language, je navrženým standardem pro reprezentaci výsledků data mining. Je podporován jak nekomerčními systémy pro vyhledávání znalostí v databázích (Knowledge Discovery Support Engines, KDDSE) tak komerčními firmami jako je IBM. Oracle, SAS a SPSS. Výsledky dolování je pak možné v GRR vizualizovat pomocí PMML-Vizualizéru (http://soleunet.ijs.si/website/other/pmml.html)
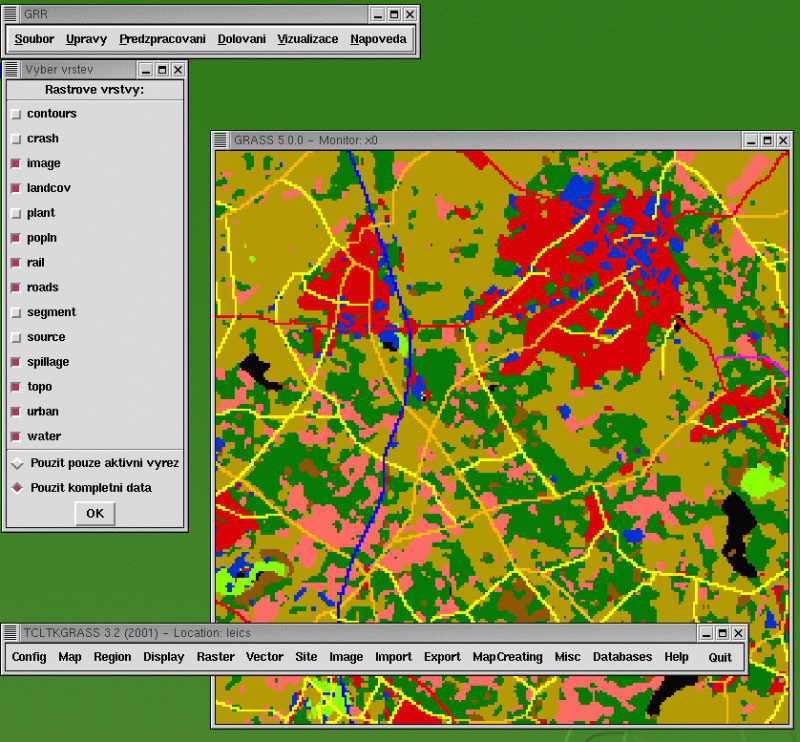
Obr. 2 Ukázka uživatelského rozhraní GRR
Geografická data, která máme k dispozici pro demonstrování práce systému GRR, pokrývají severozápadní část Leicestershire v Anglii. Jde o rastrová data pokrývající výřez velikosti 12km x 12km. V této oblasti jsou dvě větší města (Loughborough a Shepshed), hustá síť silnic různých kategorií (včetně dálnice), vede tudy železnice a protéká tudy řeka (Soar). Část této oblasti je spíše nížinatá (sever a východ) a část pokrývá vysočina.
Data obsahují tyto datové vrstvy:
Uveďme zde příklad klasifikační úlohy na výše popsaných geografických datech. V této úloze nám půjde o to, na základě zadané množiny vstupních atributů a výstupního atributu vygenerovat rozhodovací strom. Budeme generovat rozhodovací strom, který na základě hodnot pro daný bod ve vrstvách image, popln, rail, roads, segment, spillage, topo, urban a water (vstupní atributy) přiřadí odpovídající kategorii povrchu (výstupní atribut je tedy vrstva landcov).
Nejprve je nutné si v nabídce 'Soubor->Import' zvolit vrstvy dat z GRASSu, se kterými budeme dále chtít v GRR pracovat. Pomocí mabídky 'Úpravy->Vzorek' rozdělíme data na učící a testovací množinu. Jako učící bylo použito 10% náhodně vybraných příkladů, zbytek byl použit pro otestování.
Nyní již můžeme přejít k samotné klasifikační úloze. V nabídce 'Dolování->Klasifikace' zvolíme položku 'Rozhodovací strom'. Zobrazí se nám nabídka, kde můžeme zvolit vstupní a výstupní atributy. Zde jsou nám k dispozici vrstvy, které jsme nastavili v nabídce 'Soubor->Import'.V nabídce je také možné nastavit různé parametry, ovlivňující následné vygenerování rozhodovacího stromu, jako např. míra ořezávání, počet kroků křížové validace apod. Poté, co nastavíme požadované hodnoty (vstupní/výstupní atributy, příp.další parametry), systém vygeneruje na základě učících dat rozhodovací strom.V našem případě byla zvolena míra ořezávání = 1%, křížová validace = 10 kroků.
Samotný rozhodovací strom se standardně vygeneruje na základě náhodně vybraném vzorku dat (tzv. učící množina), který pokrývá 10% vstupních dat. Získaný strom zobrazíme buď pomocí systému R nebo pomocí vizualizátoru ('Vizualizace->Vizualizovat model') (viz obr. 3). V následující ukázce části PMML kódu za záhlavím (zde neuvádíme) následují deklarace jednotlivých atributů
... <DataField name="o__att2o" displayName="topo" optype="continuous"> </DataField> <DataField name="o__att3o" displayName="image" optype="continuous"> </DtaaField> <DataField name="o__att4o" displayName="popln" optype="continuous"> </DataField> ...
V druhé části je popis vlastního rozhodovacího stromu. Pro každý uzel stromu Node je uveden počet učících příkladů recordCount, které "prošly" tímto uzlem a nejčastější třída score . Logická podmínka je u v poli Predicate s názvem atributu field, logickým operátorem operator a konstantou value (viz uzel popln>=0.5 na obr. 3).
<Node recordCount="5760" score="5" x-nodeId="id1">
<Node recordCount="601" score="2" x-nodeId="id2">
<Predicate field="o__att4o" operator="greaterOrEqual" value="0.5"/>
Je-li uzel listem, je definován počet příkladů pro každou třídu
<ScoreDistribution value="1" recordCount="27"/>
<ScoreDistribution value="2" recordCount="516"/>
<ScoreDistribution value="3" recordCount="1"/>
<ScoreDistribution value="4" recordCount="4"/>
<ScoreDistribution value="5" recordCount="28"/>
<ScoreDistribution value="6" recordCount="24"/>
<ScoreDistribution value="7" recordCount="1"/>
<ScoreDistribution value="8" recordCount="0"/>
</Node>
uzel je ukončen </Node> a pokračuje popis další cesty ve stromu.
<Node recordCount="5159" score="5" x-nodeId="id3">
<Predicate field="o__att4o" operator="lessThan" value="0.5"/>
<Node recordCount="4189" score="5" x-nodeId="id6">
<Predicate field="o__att3o" operator="lessThan" value="110.5"/>
<Node recordCount="549" score="4" x-nodeId="id12">
<Predicate field="o__att3o" operator="lessThan" value="76.5"/>
<Node recordCount="479" score="4" x-nodeId="id24">
<Predicate field="o__att3o" operator="greaterOrEqual" value="41"/>
<Node recordCount="103" score="1" x-nodeId="id48">
<Predicate field="o__att9o" operator="greaterOrEqual" value="7.5"/>
<Node recordCount="47" score="1" x-nodeId="id96">
<Predicate field="o__att2o" operator="lessThan" value="48.5"/>
<ScoreDistribution value="1" recordCount="0.79"/>
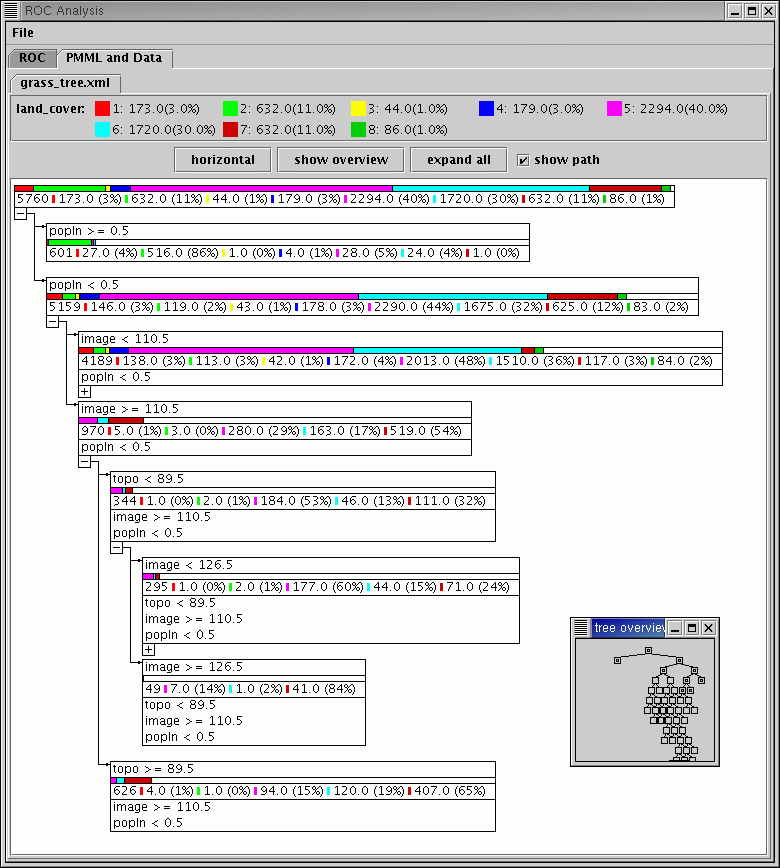
Obr. 3 Vizualizace rohodovacího stromu
Vrstva, která je zobrazena na obr.3 byla vytvořena následným oklasifikováním všech vstupních dat podle získaného rozhodovacího stromu. Vytvořit a zobrazit tuto novou vrstvu můžeme pomocí funkce ‚Export do GRASSu' v nabídce ‚Vizualizace'.

Obr. 4 Výsledek klasifikace
Pro srovnání uvádíme očekávaný výsledek. Vrstva landcov je na obr. 5.
Výsledek klasifikace na obr. 4 se od očekávaného výsledku příliš neliší. Některé detaily jsou dokonce na obr. 4 lépe viditelné. Rozhodovací strom však vůbec neklasifikuje 3. třídu - doly-lomy (světle zelené oblasti na obr. 5). Vzhledem k celému obrázku se totiž vyskytují jen velmi málo. Tento nedostatek se však dá odstranit lepší volbou vzorkování, které by zajistilo dostatečné zastoupení všech tříd (typů povrchů) v učící množině.
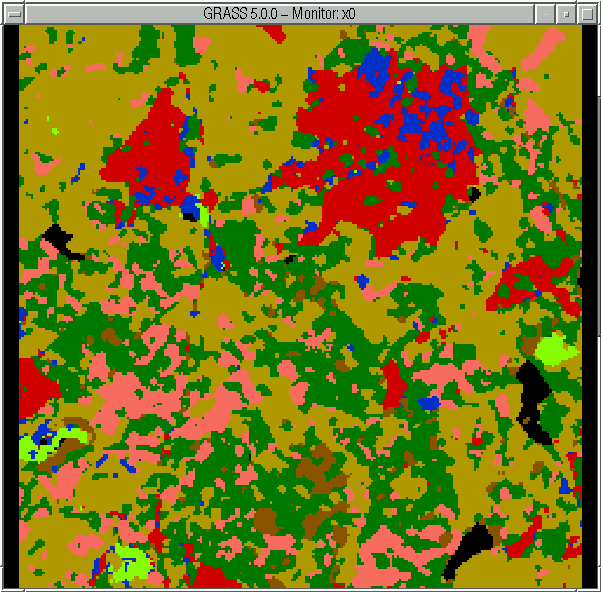
Obr. 5 Původní vrstva landcov
GRR je snadno použitelný s jiným GISem. Stačí pouze implementovat rozhraní mezi R resp. GUI GRR a konkrétním informačním systémem.
V nejbližší době chystáme rozšíření o další metody předzpracování, zvláště metody pro výběr významných atributů. Pozornost bude věnována také sofistikovanějším metodám vzorkování. Pro zpracování většího objemu dat, které není možno systémem R zpracovat, připravujeme metody aktivního učení, kdy systém sám vybírá podmnožinu dat pro dolování. Věříme, že spojením těchto metod bude možné generovat i modely velmi rozměrných dat.
Autoři děkují Dietrichu Wettsereckovi za poskytnutí PMML vizualizéru.