
RNDr. Tomáš Hlásny1, RNDr. Frantisek Ďurec,2
1: katedra geografie, laboratórium GIS
Univerzita Mateja Bela
Tajovského 40
974 01 Banská Bystrica
E - mail: hlasny@fpv.umb.sk, www.tomgis.sk
2: Štátny zdravotný ústav
Cesta k nemocnici 1
975 56, Banska Bystrica,
E - mail: durec@szubb.sk
Uncertainty is an omnipresent phenomenon randomly biasing attributes, locations and time, and in some cases even disrupting spatial, attribute and temporal topology. It affects a primary geodata structure, what is caused by inaccuracy of used technology, sampling error, geodata temporal variability, or uncertainty of remote sensed imagery classification. Variety of uncertainty sources grounds in the analytical part of geodata processing, such as spatial interpolation, classification or various syntheses. A specific area is many times inexact interpretation of the results of respective analyses, where different legislative factors might cause the ambiguity, or uncertainty of the analytically unambiguous decisions.
This contribution focuses on certain aspects of spatial uncertainty analyses, especially in the field of spatial classification. Since resultant uncertainty is almost always consequential of more uncertainty sources, we also focused on fuzzy sets synthesis by means of triangular norms/conorms capabilities. From this point of view we distinguished so-called partial uncertainty sources, which result in uncertain position of individual categories and complex uncertainty zone given by certain synthesis of them.
Neurčitosť je všadeprítomný fenomén, náhodne vychyľujúci atribúty, polohy, čas a v určitých prípadoch narúšajúci atribútovú, priestorovú a časovú topológiu geoobjektov. Postihuje na jednej strane primárnu štruktúru geoúdajov, čo je zapríčinené faktormi ako je nepresnosť meracích prístrojov, chyba z výberu, časová exspirácia údajov, alebo nepresnosť klasifikácie údajov DPZ. Celkovú úroveň neurčitosti je potrebné chápať ako výslednicu viacerých faktorov. V príspevku sme sa zamerali na ich analýzu, možnosti syntézy a interpretáciu výslednej štruktúry. Pri tomto ponímaní pri vymedzení jednotlivých kategórií vzniká tzv. parciálna tranzitná zóna, alebo zóna neurčitosti. Pre potreby praxe je vhodné vyjadriť uvedenú zónu ako jednu štruktúru, čo sme realizovali syntézou čiastkových neurčitostí využitím vybraných nástrojov teórie fuzzy množín. Týmto spôsobom je definovaná tzv. komplexná zóna neurčitosti.
Intenzívny vývoj metód pre vyčerpávajúcu analýzu priestorových údajov a zvyšujúce sa požiadavky praxe na presnosť, vyplynuli do potreby integrácie faktora neurčitosti do všetkých fáz riešenia GIS projektu. Vplyv tohto faktora je mimoriadne významný najmä v kritických odvetviach hodnotenia dopadu antropických aktivít na prostredie, alebo pri hodnotení dopadu vplyvov prostredia na človeka, ako je napr. analýza šírenia chorôb a škodcov, monitoring rádioaktivity, či analýza povodňových rizík, a následné využívanie týchto informácií v procese rozhodovania. Viaceré štúdie potvrdzujú, že kumulácia množstva zdrojov neurčitostí postihujúcich jednotlivé fázy realizácie GIS projektu, od primárneho zberu údajov, cez jednotlivé analýzy, modelovanie a simulácie, až po záverečnú interpretáciu výsledkov môže výsledky rozhodovacieho procesu významne vychýliť. Význam tejto problematiky potvrdzuje aj rastúce množstvo prác venovaných rozličným aspektom neurčitosti geoúdajov publikovaných v renomovaných periodikách. Tieto skutočnosti si vyžiadali vývoj samostatnej oblasti spracovania geoúdajov - tzv. manažment neurčitostí (uncertainty management) (Motro 1996, McBratney 1992). V príspevku sme sa zamerali na niektoré aspekty neurčitosti v priestorových analýzach, všeobecný teoretický rozbor tejto problematiky a návrh metodiky pre hodnotenie dopadu rozličných zdrojov neurčitosti v oblasti klasifikácie priestorových údajov.
Neurčitosť je všadeprítomný fenomén, náhodne vychyľujúci atribúty, polohy, čas a v určitých prípadoch narúšajúci atribútovú, priestorovú a časovú topológiu geoobjektov. Postihuje na jednej strane primárnu štruktúru geoúdajov, čo je zapríčinené faktormi ako je nepresnosť meracích prístrojov, chyba z výberu, časová exspirácia údajov, alebo nepresnosť klasifikácie údajov DPZ. Široké spektrum zdrojov neurčitostí leží v analytickej časti spracovania geoúdajov, napr. pri využití rozličných interpolačných algoritmov, klasifikácií údajov, rozličných typoch syntéz a pod. V tejto fáze je za mimoriadne významný krok potrebné považovať problematiku syntéz viacerých zdrojov neurčitosti s rozličnou štruktúrou a genézou, čo vyžaduje využitie špecializovaných algoritmov. V takýchto prípadoch sa stretávame s javom kumulácie, alebo prenosu neurčitosti, čo môže mať z praktického hľadiska mimoriadne vážne následky. Algoritmy pre riešenie tohto javu uvádzajú napr. Burrough (1986), Šmelko (2000) a ďalší. Špecifickou oblasťou manažmentu neurčitosti je subjektívny vplyv interpretácie výsledkov jednotlivých analýz pre potreby praxe, kde sa mnohokrát nie je možné riadiť exaktnými postupmi, ale je potrebné zohľadniť napr. legislatívne faktory. V tomto kroku mnohokrát jednoznačný výsledok určitej analýzy nadobudne viacznačný význam - stane sa neurčitým.
Zhu (1997) rozlišuje dva typy neurčitosti - prvá sa vzťahuje k neurčitosti polohy geoelementu v príslušnej kategórií a druhá vyjadruje odchýlku geoelementu od tzv. prototypu kategórie od ktorej patrí. S týmto členením korešpondujú aj dva typy neurčitosti v zmysle Browna (1998) - nejednoznačnosť v atribúte (attribute ambiguity) a neurčitosť v polohe (spatial vagueness). K uvedenému členeniu sa viažu aj metódy pre kvantifikáciu neurčitosti. V zmysle Eastmana (1999) je ako dominantné zdroje neurčitosti možné označiť:
V prípade bodu týkajúceho sa abstrakcie, ktorá je významným zdrojom neurčitosti pri akomkoľvek modelovaní vychádzame z definície podľa Harveya (1969, p. 448), ktorý uvádza že "akýkoľvek prírodný systém je nekonečne komplexný a modelovať a analyzovať ho je možné až po jeho abstrakcií". V prípade spracovávania priestorových údajov je jeden z prístupov k abstrakcií priestorových systémov teselácia (Laurini a Thompson 1994), pri ktorej dochádza k zjednodušeniu geoobjektov ich rozložením do série pravidelných, nepravidelných, umelých alebo prirodzených útvarov. Tento proces je sprevádzaný kontrolovaným znižovaním informačného obsahu zameraním sa len na jeden, alebo niekoľko hierarchicky usporiadaných systémov. Vzhľadom na rozmanitosť prístupov k teselácií je kvantifikácia tohto typu neurčitosti problematická.
Algoritmy pre hodnotenie neurčitosti klasifikácie sa významne líšia v závislosti od charakteru spracovávaných údajov. V prípade kvalitatívnych údajov je možné neurčitosť pochádzajúcu z presnosti klasifikácie určiť pomocou chybovej matice mierami ako je percento korektne klasifikovaných pixelov, RMSE (Root Mean Square Error) chyba alebo Kappa indexy (Pontius 2000, Lilesand a Kiefer 1994). V tejto oblasti sú významné práce Zhu (1998) a Zhu et al. (2001), ktorí sa venovali najmä terénnemu mapovaniu a klasifikácii pôdnych typov. V prípade neurčitosti kvantitatívnych údajov je obvyklé neurčitosti vyjadrovať opäť pomocou RMS chyby, MAE (Mean Absolute Error) chybou, príp. inou mierou (Isaaks a Srivastava 1989).
Postupov pre kvantifikáciu týchto komponentov celkovej neurčitosti je vyvinuté väčšie množstvo. Chyba priestorových údajov je vždy určená ako rozdiel medzi mapovanou t a skutočnou hodnotou x na i polohách.
e i = xi - ti
Tieto hodnoty sa označujú ako reziduály a slúžia pre určenie niektorej z komplexných mier chyby. Z hľadiska analýzy neurčitosti je celkovú chybu potrebné rozložiť na jej systematickú a náhodnú zložku, ktorá spôsobuje celkovú variabilitu chýb okolo ich priemeru a je pre tento typ analýzy kľúčová. Pre výpočet týchto zložiek celkovej chyby platia nasledovné vzťahy:
pričom celková chyba modelu je vyjadrená tzv. strednou kvadratickou chybou my, ktorá je pre jedno meranie formulovaná ako

Dôležitá skutočnosť je, že hodnoty reziduálov sú normálne rozdelené (v opačnom prípade je potrebné prehodnotiť štruktúru testovaného modelu, alebo metodiku testovania), vzhľadom na to, že charakter ich rozdelenia početnosti poskytuje potrebné východisko pre komplexnú analýzu neurčitosti.
Pojem neurčitosti je od šesťdesiatych rokov nerozlučne spätý s teóriou fuzzy množín, ktorá ponúka široké spektrum nástrojov pre popis, modelovanie, analýzu a prípadnú syntézu rozličných typov neurčitosti. Na tejto úrovni je neurčitosť vyjadrená kontinuálnym stupňom členstva uvažovaného prvku v kategóriách, do ktorých je prvok inak zaraďovaný jednoznačne (obr. 1). Charakter tohto prechodu je podmienený množstvom faktorov a vyžaduje znalosti určitých prvkov správania analyzovaného javu. Základná myšlienka klasifikácie založenej na využití neostrých množín je predpoklad, že ľudské vnímanie je nedokonalé a klasifikované prvky zriedka dokonale zodpovedajú povahe kategórií do ktorých sú zaraďované (Zadeh 1965). Stupeň členstva v jednotlivých fuzzy triedach môže byť mylne interpretovaný ako pravdepodobnosť príslušnosti ku kategórií. Rozdiel je v prvom rade v interpretácii, vzhľadom na to, že v prípade teórie pravdepodobnosti predpokladáme, že pracujeme len s jednou triedou a určujeme pravdepodobnosť, že príslušný prvok k nej prináleží. Naopak, v prípade využitia teórie neostrých množín predpokladáme prítomnosť viacerých tried a objektom výskumu je, nakoľko prvok do ktorej triedy fyzicky prináleží.
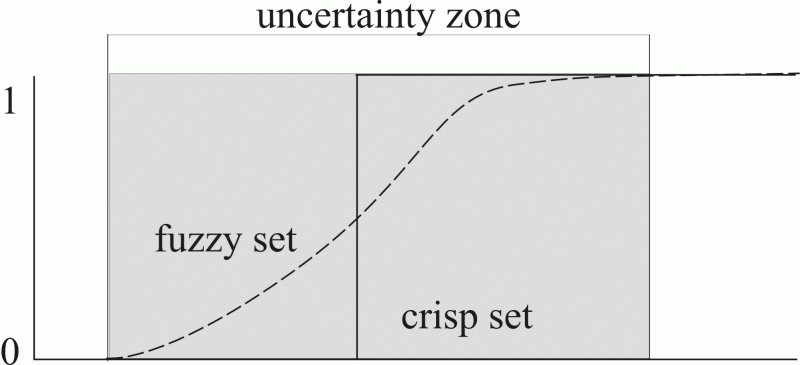
Obr.1 Štruktúra tranzitnej zóny (zóny neurčitosti) pri klasifikáciu prvku do dvoch kategórií.
Charakter prechodu medzi jednotlivými kategóriami je definovaný pomocou tzv. fuzzy funkcií. V praxi sa najčastejšie stretávame s využitím symetrických trojuholníkových, trapézoidných alebo tzv. "bel shaped" funkcií. Ich správanie je definované pomocou niekoľkých premenných, manipulácia s ktorými umožňuje flexibilný popis správania rozličných typov neurčitosti (obr. 2).

Obr. 2 Bell shaped fuzzy funkcia a jej parametre
Mierne odlišným prístupom k hodnoteniu neurčitosti v priestorovej klasifikácií je využitie konceptu "rough" množín podľa Ahlquista et al. (1998) a Pawlaka (1982). Tento koncept vychádza z predpokladu, že neurčitá množina je definovaná svojou dolnou a hornou aproximáciou. "Rough" množina je teda definovaná párom množín 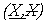 , ktoré vyjadrujú uvedenú spodnú a vrchnú aproximáciu.
, ktoré vyjadrujú uvedenú spodnú a vrchnú aproximáciu. 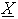 je označovaná ako spodná aproximácia a je vždy podmnožinou
je označovaná ako spodná aproximácia a je vždy podmnožinou 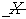 . V prípade, že sa klasifikovaný bod nachádza v spodnej aproximácií patrí triede do ktorej je klasifikovaný, v opačnom prípade sa bod v tejto triede nenachádza. V prípade že sa bod nachádza v zóne
. V prípade, že sa klasifikovaný bod nachádza v spodnej aproximácií patrí triede do ktorej je klasifikovaný, v opačnom prípade sa bod v tejto triede nenachádza. V prípade že sa bod nachádza v zóne 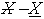 hovoríme, že jeho poloha je neurčitá.
hovoríme, že jeho poloha je neurčitá.
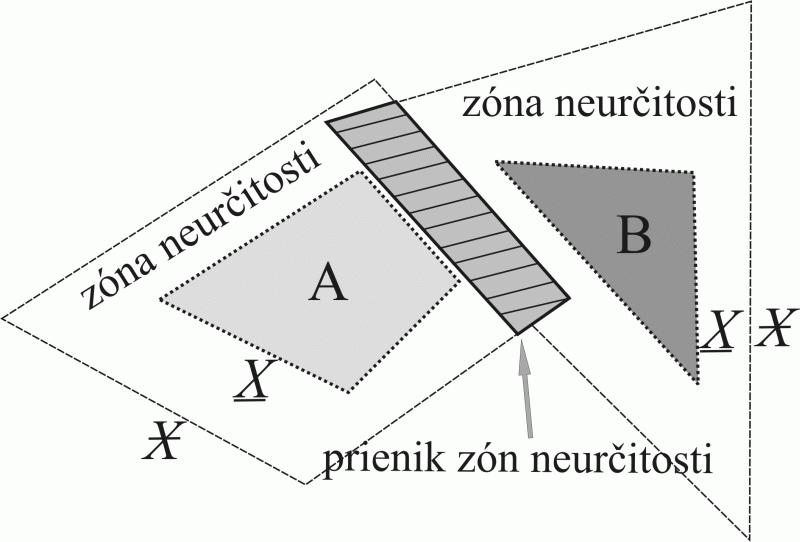
Obr. 3 "Rough" množiny A a B vyjadrená svojou spodnou a vrchnou aproximáciou 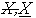 , zónou neurčitosti definovanou ako
, zónou neurčitosti definovanou ako 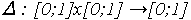 .
.
Ďalší prístup k hodnoteniu neurčitosti hraníc kategórií uvádza Blakemore (1984) recte Burrough (1986). Tento prístup sa týka neurčitosti vektorizovaných hraníc, ktoré nezodpovedajú priebehu objektov reálneho sveta.
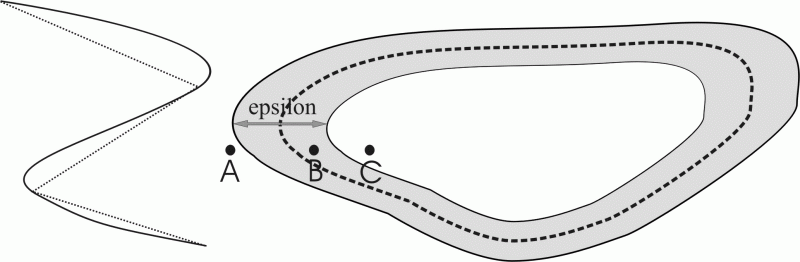
Obr. 4 Spôsob aproximácie reálneho objektu vektorizovanou líniou a vniknutá zóna epsilon. Pri tomto ponímaní sa bod A nachádza jednoznačne mimo polygónu, bod C v jeho vnútri a a bod B nemôže byť jednoznačne klasifikovaný (upravené podľa Burrough, 1986).
Autor vyčlenil tzv. zónu epsilon, ktorá vyjadruje napr. neurčitosť polohy bodu v rámci polygónu (obr. 4), ale má samozrejme aj širšie uplatnenie. Ako je možné vidieť, v závislosti od charakteru tejto zóny a štruktúry spracovávaných údajov, môže v extrémnom prípade dôjsť dokonca k narušeniu priestorovej topológie. Tento zdroj neurčitosti priestorových údajov je však natoľko špecifický, že sa nestretávame s empirickými štúdiami zameranými týmto smerom.
Ako bolo uvedené, v praxi sa takmer vždy stretávame s väčším množstvom neurčitostí pochádzajúcich buď z prirodzenej variability spracovávaných systémov, alebo z charakteru vykonávaných analýz a spracovania údajov. Každý z týchto zdrojov podmieňuje polohu a príp. charakter prechodu medzi kategóriami špecifickým spôsobom (stupňom členstva v jednotlivých kategóriách, tranzitnou zónou vyššie uvedených rough množín, alebo šírkou zóny epsilon). Pre potreby praxe je vhodné tieto parciálne úrovne neurčitosti syntetizovať a využívať komplexný model neurčitosti. Operátorov umožňujúcich realizáciu tohto typu analýz je k dispozícií väčšie množstvo. Vzhľadom na to, že pre vyjadrenie štruktúry čiastkových neurčitostí budú využité vybrané fuzzy funkcie, zamerali sme sa na viac-hodnotové ekvivalenty binárnych operátorov AND a OR tzv. t-normy a conormy. (Navara a Olšák 2002, Klir et al. 1997). Binárna operácia je t-normou ak spĺňa nasledovné kritériá:

Existuje niekoľko modelov t-norm, ďalšie môžu byť odvodené. Uvádzame nasledovné:

Vzhľadom na to, že tieto pravidlá sú asociatívne, ďalšie premenné môžu byť jednoducho pridávané. Okrem týchto nástrojov je možné využiť niektoré ďalšie agregačné operátory, napr. flexibilnú sériu vážených lineárnych kombinácií zdrojových modelov a pod. Detailný rozbor týchto prístupov je oblasťou ďalšieho výskumu.
Cieľom príspevku je navrhnúť metodiku integrácie faktora neurčitosti do procesu priestorovej klasifikácie. Exaktná definícia týmto spôsobom vzniknutej zóny neurčitosti, ktorá oddeľuje jednotlivé kategórie, či už využitím nástrojov teórie neostrých množín, uvedených rough množín, alebo definovaním zóny epsilon vyžaduje komplexnú analýzu zdrojov neurčitosti zaťažujúcich jednotlivé údajové hladiny. Zo všeobecného hľadiska pri priestorovej klasifikácií rozoznávame dva pojmy - určitý počet neprekrývajúcich sa množín a príslušné množstvo priestorových údajov. Kombináciou množín a údajov sú definované triedy, alebo kategórie (Ahlquist et al. 1998). Brown (1998) označuje klasifikáciu ako proces kombinácie rozličných javov do tried alebo typov, čo označuje ako formu atribútovej generalizácie.
Pre hodnotenie neurčitosti v priestorovej klasifikácií založenej na syntéze viacerých zdrojov neurčitosti sme vypracovali metodiku umožňujúcu zohľadnenie špecifickej štruktúry čiastkových neurčitostí a ich flexibilnú syntézu. Ako podkladové údaje boli použité výsledky monitoringu radónového potenciálu v modelovom území Štiavnické Bane (Hlásny et al. 2003). Ako zdrojové údaje boli využité bodové výberové údaje získané priamym meraním v teréne. Následne bol metódou ordinárneho krigingu odvodený komplexný model radónového poľa. Pre klasifikáciu poľa do kategórií "presahujúce kritickú hranicu" a "nepresahujúce kritickú hranicu" bolo použité explicitne stanovené klasifikačné kritérium hodnoty tretieho kvartilu meraných údajov (obr. 5). Ako dominantné zdroje neurčitosti boli určené:
Okrem uvedených zdrojov neurčitosti je možné použiť polohovú neurčitosť zdrojových údajov, neurčitosť explicitne stanoveného klasifikačného kritéria a pod. Pre jednoduchosť riešenia budeme uvažovať len uvedené faktory.

Obr. 5. Binárna klasifikácia modelu radónového poľa na základe hodnoty tretieho kvartilu s príslušným histogramom a vyznačenou prahovou hodnotou
V prvom kroku analýzy neurčitosti boli charakterizované tzv. čiastkové úrovne neurčitosti. Pre obidva uvažované faktory boli odvodené základné štatistické charakteristiky vypočítaných reziduálov a ich tvar funkcie rozdelenia početnosti, ktorá súčasne determinuje štruktúru zóny neurčitosti. Jej detailný priebeh je kontrolovaný určitým počtom kontrolných bodov, ktoré sú odvodené z príslušnej funkcie rozdelenia početnosti. Výsledky tohto typu analýzy je možné vidieť na obr. 6-7. Vzhľadom na to, že z praktických dôvodov nás zaujíma len časť zóny neurčitosti ležiaca smerom k nižším hodnotám, budeme pre jej vyjadrenie používať klesajúci typ fuzzy krivky.

Obr. 6. Klasifikácia modelu radónového poľa s ohľadom na neurčitosť pochádzajúcu z jeho časovej variability a príslušný histogram, vyjadrujúci časť územia jednoznačne presahujúcich prahovú hodnotu (1), jednoznačne nepresahujúcich prahovú hodnotu (0) a časť územia s určitým stupňom neurčitosti polohy v daných kategóriách.
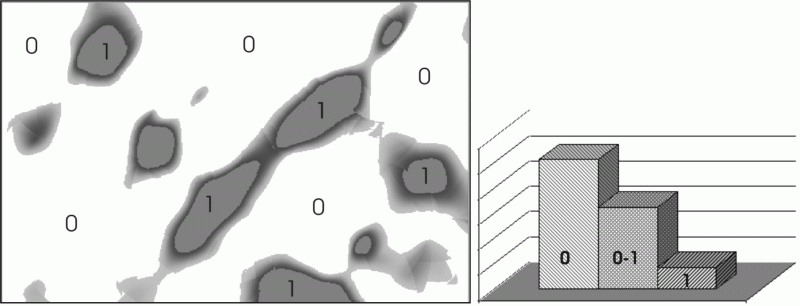
Obr. 7. Klasifikácia modelu radónového poľa s ohľadom na neurčitosť pochádzajúcu z interpolácie a príslušný histogram vyjadrujúci časť územia jednoznačne presahujúcich prahovú hodnotu (1), jednoznačne nepresahujúcich prahovú hodnotu (0) a časť územia s určitým stupňom neurčitosti polohy v daných kategóriách.
Ako je možné vidieť, časová variabilita analyzovaného javu je mimoriadne vysoká, čo sa prejavilo aj v štruktúre zóny neurčitosti. Analýza časovej neurčitosti je mimoriadne komplexná oblasť, vzhľadom na to že v priestore je možné vymedziť zóny, kde je tento jav mimoriadne intenzívny, a naopak relatívne stabilné zóny. Táto problematika je oblasťou ďalšieho výskumu.
V prípade neurčitosti vplyvom nepresnosti pochádzajúcej z interpolačného algoritmu je situácia mierne odlišná. Model bol skonštruovaný relatívne presne, zdrojové pole bolo dostatočné husté a korektne rozmiestnené. Tieto skutočnosti sa prejavili aj na príslušnom modely vyjadrujúcom praktickú implikáciu tohto zdroja neurčitosti (obr. 7).
Vzhľadom na to, že pre vyjadrenie jednotlivých zón neurčitosti bola využitá Gausova krivka, ich klasifikáciou je možné vytvoriť kategórie, ktoré umožňujú interpretáciu "časť územia z 90% pravdepodobnosťou spadajúca do kategórie 1", "časť územia z 80% pravdepodobnosťou spadajúca do kategórie 0" a pod. Túto úvahu je však možné využiť len v prípade, že pre vyjadrenie stupňa členstva prvku v príslušnej kategórií bola využitá Gausova krivka. Vo všeobecnosti sa je v prípade využitia teórie neostrých množín potrebné vyhnúť interpretácií príslušnosti prvku v danej množine ako pravdepodobnosti príslušnosti k určitej kategórií. V tejto súvislosti totiž nehovoríme o pravdepodobnosti, ale o fyzickom stupni príslušnosti prvku k danej kategórií. Problém je v tom, že rozličné aplikácie vyžadujú rozlične interpretované výsledky a pravdepodobnosť je miera pre potreby praxe mnohokrát prijateľnejšia ako stupeň členstva prvku vo viacerých kategóriách. Z matematického hľadiska je však táto úvaha nekorektná.
Kvantifikácia a priestorové vyjadrenie čiastkových zdrojov neurčitosti ponúka jedinečný pohľad na ich praktické implikácie. Pre praktické potreby je syntézou týchto modelov vhodné skonštruovať komplexnú zónu, ktorá môže slúžiť ako významný podklad v rozhodovacom procese. K tejto syntéze je možné pristupovať viacerými spôsobmi. V prípade, že sú neurčitosti kvantifikované formou fuzzy funkcií, je možné využiť sériu fuzzy t-norm a konorm (prienikov a zjednotení), ktoré však prinášajú problémy pochádzajúce z charakteru týchto operácií. V prípade t-norm je najvýraznejší problém, že nulová hodnota jedného čiastkového zdroja neurčitosti sa premietne do výsledného modelu, bez ohľadu na štruktúru ostatných modelov (obdobne ako v prípade binárneho operátora AND). Naopak, v prípade konorm (zjednotení) obdobná situácia nastáva v prípade hodnôt 1. Riešením obidvoch problémov môže byť využitie odlišných agregačných operátorov, čo je oblasťou ďalšieho výskumu. Obrázky 8 a 9 vyjadrujú výsledky prienikov a zjednotení vyššie uvedených modelov s vyznačenou časťou územia presahujúcou hranicu 0.9. Túto časť územia je z hľadiska neurčitosti priradenia k jednej, alebo druhej kategórií možné považovať za kritickú.

Obr. 8. Výsledok zjednotenia vyššie uvedených zón neurčitosti využitím max-conormy a výsledok klasifikácie tohto modelu ku kritickej hodnote 0.9.

Obr. 9. Výsledok prieniku vyššie uvedených zón neurčitosti využitím minimovej t-normy a výsledok klasifikácie tohto modelu ku kritickej hodnote 0.9.
Ako je možné vidieť na obr. 8-9, syntetizácia čiastkových zdrojov neurčitosti nie je jednoznačný proces. Uvedené modely vyjadrujú len dva z možných stavov aproximujúcich štruktúru komplexnej zóny neurčitosti. Problematické je, že v podstate neexistuje známy stav, ktorý chceme dosiahnuť, takže aj testy presnosti sú nerealizovateľné. Výber vhodného agregačného operátora je vždy potrebné starostlivo zvážiť z hľadiska zamerania výskumu.
Predbežný výskum naznačuje, že vzhľadom na štruktúru podkladových materiálov a charakter uvažovaných analýz, môže uvedená tranzitná zóna, alebo zóna neurčitosti pokrývať významnú časť územia. Táto skutočnosť vyžaduje prijatie špecifických opatrení v procese rozhodovania pre využívanie podkladov zohľadňujúcich faktor neurčitosti uvedeným spôsobom. Cieľom ďalšieho výskumu by mala byť analýza možností minimalizácie tejto zóny, jednak na úrovni prípravy podkladových materiálov aj z hľadiska jednotlivých analytických postupov a manipulácie s čiastkovými neurčitosťami.
Vzhľadom na požiadavky doby sa manažment neurčitosti stáva významným komponentom manipulácie s geoúdajmi. V príspevku sme naznačili niektoré aspekty tohto fenoménu, týkajúce sa predovšetkým problematiky priestorovej klasifikácie. Manipulácia s väčším množstvom zdrojov neurčitosti so špecifickým praktickým prejavom je teoreticky aj prakticky náročnou oblasťou. Ich syntéza využitím uvedených agregačných operátorov naráža na množstvo praktických problémov. Využívanie prienikov a zjednotení pri tomto type syntéz, či už na úrovni binárnych operátorov, alebo ich viac-hodnotových ekvivalentov je v praxi mnohokrát nepostačujúce, najmä v prípadoch, keď sú tieto premenné korelované, alebo keď je potrebné niektoré z nich prioritizovať, čiže ich význam je relatívne vyšší. V tomto prípade je vhodné využiť skôr niektorú z metód lineárnych vážených kombinácií.
Ako bolo prakticky demonštrované v prípadovej štúdií, kumulácia viacerých zdrojov neurčitosti má natoľko významné praktické implikácie (čiže napr. zóna o ktorej sa nie je možné jednoznačne vyjadriť, ku ktorej kategórií prináleží zaberá viac ako 20% celkovej rozlohy územia), že ich je potrebné zohľadniť v rozhodovacom procese. Samostatnou oblasťou manažmentu neurčitosti je prenesenie týmto spôsobom realizovaných analýz do praxe, čím sa dostávame do oblasti tzv. risk manažmentu. Ma tejto úrovni je vzhľadom na charakter neurčitosť vstupných údajov a samozrejme množstvo ďalších faktorov, potrebné prijať prípustné hodnoty rizika (mnohokrát zákonom, alebo smernicou), od ktorých sa odvíja ďalší rozhodovací proces.