|
|
|


|
GISáček |
|
|
|
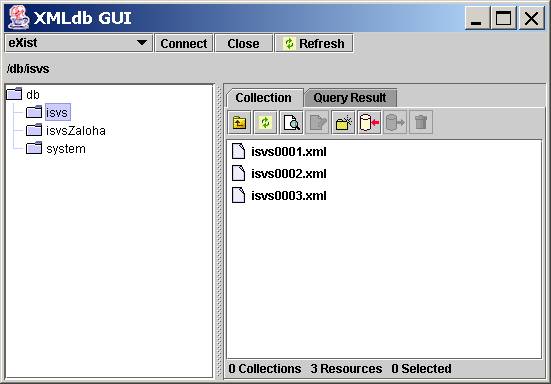
Metainformační systém založený na XMLJosef Mikloš AbstractThis thesis investigates the design and implementation of a Web-based XML meta-information system for geospatial data. Metadata may exist in forms other than ones compliant format. The design of a system covers multiform store away. XML-based metainformation system stores metadata content by force of a native XML database. Available is support for common standards as the FGDC CSDGM, MI ISVS and ISO 19115 for XML geospatial metadata. System allows a user to query metadata independently on original form. Import and export of metadata records is viable by XML interchange formats. Primary benefit of this solution is flexibility for custom-made application that using a set of technologies currently evolving in the context of XML, like XSLT, XPath, DOM etc. AbstraktDiplomová práce se zabývá návrhem a implementací metainformačního systému pro prostorová data, který je založen na XML. Novým přínosem práce je technické řešení spočívající v ukládání metadat prostřednictvím nativní XML databáze. Navržený systém umožňuje evidovat metadata podle různých standardů a obsahuje podporu pro běžně používané standardy. Uživatelé systému mohou vyhledávat v metadatech nezávisle na použitém standardu. Prezentované řešení staví na flexibilitě jazyka XML a přidružených technologiích, které umožňují přizpůsobení systému konkrétním požadavkům. ÚvodProblematika, která blízce souvisí s tématem diplomové práce se týká metadat pro prostorová data, efektivního využití metadat a standardizace v této oblasti. Metadata obecně popisují vlastnosti samotných dat a jsou jejich integrální součástí. Optimální využití jakýchkoli dat je závislé na znalosti odpovídajících metadat. Z důvodu stále vzrůstajícího množství dat je potřeba evidenci metadat vhodným způsobem organizovat. K tomuto účelu slouží metainformační systémy. Tato diplomová práce se zabývá tvorbou prototypu metainformačního systému pro prostorová data. Novým aspektem je technické řešení navrženého metainformačního systému, které staví na konceptech jazyka XML. Podnětem pro takovéto řešení je fakt, že dosavadní metainformační systémy byly zpravidla budovány s ohledem na konkrétní standard pro metadata prostorových dat. Metadata u takovýchto systémů byla většinou ukládána prostřednictvím RSŘBD, což sebou neslo nutnost definovat datový model pro uložení metadat. Takovéto systémy byly z pohledu přijetí nového standardu, popřípadě změny stávajícího standardu málo flexibilní. Rovněž musely navíc implementovat mechanizmus pro import a export metadat ve výměnném formátu, aby nebyly uzavřené vůči svému okolí. Hlavní myšlenkou nově prezentovaného přístupu je využití výměnného formátu metadat, který využívá jazyk XML. Výměnný formát je nezávislý na použitém systému a platformě. Metainformační systém tak eviduje metadata ve formě výměnného formátu, tzn. v podobě, v jaké jsou metadata do systému importována. Pro takovýto metainformační systém pak není nutné definovat datový model pro ukládání metadat, protože XML forma obsahuje kromě samotných dat i popis jejich struktury. Takovýto přístup umožňuje integrovat v jednom systému data různé struktury, což v důsledku dovoluje použití různých standardů pro metadata. Kombinovaná evidence metadat podle různých standardů může být přínosná v mnoha situacích. Může řešit přechodné období, kdy se realizuje přechod z jednoho standardu na jiný. Nebo lze v jednom systému evidovat metadata podle národního a zároveň podle mezinárodního standardu. A zejména pro organizace je zajímavé evidovat ještě některá interní metadata, která jsou nad rámec používaných standardů. 1 Základní pojmyZákladní pojmy, které budou v této kapitole nastíněny se budou držet linie dané názvem diplomové práce, tedy Metainformační systém založený na XML. Nejprve bude zmíněna problematika metadat, což je hlavní předmět zájmu následně zmíněných metainformačních systému a nakonec navazuje popis jazyka XML a souvisejících technologií. 1.1 MetadataMetadaty jsou označována taková data, která vhodným způsobem popisují vlastnosti a charakter samotných dat. Podle [1] je možné metadata rozdělit na: - Metadata o metadatech, - orientační metadata, - konceptuální metadata. Metadata o metadatech popisují blíže proces tvorby samotných metadat, jedná se např. o uvedení jazyka, ve kterém jsou metadata uváděna, způsob kódování textu, časové rozlišení pořízení metadat, identifikace osoby, která metadata pořídila atd. Orientační metadata poskytují základní informaci o datech, je to zejména identifikace, název, autor, vlastník, distributor, prostorový rozsah. Konceptuální metadata již popisují samotnou strukturu dat, datové typy, hierarchii, definici v prostoru, čase. Dále lze u této kategorie uvést přesnost, kompletnost, logickou konzistenci apod. Podle zmíněného dělení metadat je patrné, že se jedná o množství doplňujících údajů, které musí uživatel znát a zadat. Pokud takováto evidence metadat nebyla prováděna systematicky a pravidelně, může narůst k nezvládnutelnému stavu. Dodatečné pořizování metadat sebou může nést problém ztráty některých informací. Využití metadat je možné na mnoha úrovních. Metadata mohou sloužit jako prostředek organizace a katalogizace datových zdrojů. Metadata mohou postihovat informace o aktuálním stavu dat a pomáhat při údržbě dat. Mohou posloužit při nalezení dat požadovaných parametrů. Pomocí metadat lze porovnávat dostupná data a vybrat ta optimální. V ne-poslední řadě nám metadata umožňují porozumět datům a následně data vhodně využít. Aby mohla být metadata na úrovni organizace, státu, nebo více států efektivně využívána, je potřeba stanovit jednotnou formu metadat a způsob jejich pořizování, to vytváří prostor pro standardy, normy, vyhlášky a legislativu. 1.2 Metainformační systémyDříve zmíněná metadata je potřeba nějakým způsobem organizovat, spravovat a zejména zpřístupnit co největšímu okruhu lidí. Tyto úkoly může plnit právě metainformační systém. Mezi základní požadavky kladené na metainformační systém patří: - Využití standardů pro metadata - Schopnost importovat a exportovat metadata ve výměnném formátu - Vyhledávání v metadatech (název, klíčová slova, popis, plošné pokrytí) - Zabezpečení metadat Klíčovým faktorem při budování metainformačního systému je právě volba standardu pro evidovaná metadata. Tato volba je ovlivněna více faktory, ale nejvíce je dána typem metainformačního systému (viz dělení metainformačních systému). Metainformační systém by neměl působit jako uzavřený celek, ale měl by nabízet možnost exportovat a importovat metadata v nezávislém výměnném formátu, rovněž by měl nabízet možnost integrace s jinými metainformačními systémy, nebo portály. Metainformační systém by měl umožňovat efektivní vyhledávání v metadatech, která eviduje, zejména by měl zohlednit specifika metadat o prostorových datech, tzn. nabízet vyhledávání zaměřené na prostorovou složku. V neposlední řadě by měl metainformační systém zajistit zabezpečení dat, např. před úmyslným poškozením, nebo zneužitím některých citlivých informací. 1.2.1 Dělení metainformačních systémůS metadaty se lze setkat v mnoha oblastech a na různých úrovních. Různorodost metadat je dána různorodostí samotných dat a možnostmi jejich využití. Tuto různorodost musí také postihovat metainformační systémy, které metadata evidují. Z tohoto pohledu lze uvést následující dělení metainformačních systémů, které uvádí [20]. - Podle charakteru obsahu - Podle zodpovědnosti za obsah - Podle použitého jazyka - Podle technologie prezentace a vstupu (editace) metadat 1.3 XMLXML [27] je jazyk používaný pro strukturovaný popis dat. Díky strukturované formě je patrný i význam dat, což je podstatné při procesu zpracování. Textový soubor vytvořený pomocí XML se označuje jako XML dokument (Obr. 1), takovýto dokument obsahuje jednak samotná značkovaná data a značkování. Značkovaná data jsou uzavřena mezi značky, značky jsou pro odlišení od samotných dat uvozeny lomenými závorkami. Základním kamenem XML je element, XML dokument se skládá z elementů, každý element má název a obsah. Obsahem elementu může být další element (elementy), nebo samotná data. Element se skládá z počáteční a koncové značky. XML nedefinuje žádné konkrétní názvy elementů, pouze pravidla pro jejich vytváření. Název elementu nesmí obsahovat mezeru a musí začínat písmenem. K elementu lze připojit atributy, každý atribut má název a hodnotu, která je uvedena v uvozovkách. Hodnota atributu např. blíže upřesňuje element. <osoba id=111> <jmeno>Josef</jmeno> <prijmeni>Mikloš</prijmeni> </osoba> Obr. 1 Jednoduchý XML dokument V rámci XML dokumentu se může vyskytovat také deklarace použitého jazyka XML (Obr. 2), tato deklarace není povinná. Pokud je ale použita, musí se vyskytovat na prvním řádku dokumentu. Součástí deklarace může být i uvedení použitého kódování textu. Pokud není kódování explicitně uvedeno, předpokládá se kódování UTF-8. <?xml version=1.0 encoding=windows-1250?> Obr. 2 Deklarace jazyka XML Zejména z důvodu automatického zpracování musí XML dokument splňovat přísnou syntaxi. Např. elementy musí mít jak počáteční, tak koncovou značku, nebo musí být použit speciální prázdný element. Hodnoty atributů musí být uzavřeny do uvozovek. Na nejvyšší úrovni smí být pouze jeden tzv. kořenový element. Programové vybavení manipulující s XML většinou odmítne zpracovat dokument, který nesplňuje syntaxi XML. Druhým omezením, které se XML dokumentů týká, je dodržení definovaných značek a dodržení vzájemných vztahů (hierarchie) mezi značkami. Deklaraci toho, jak má platný (validní) dokument vypadat určuje DTD (Document Type Definition) [27], popřípadě XSD (XML Schema Definition) [32]. Aplikace zpracovávající XML dokument tak nejdříve ověří správnost syntaxe, a poté může ověřit platnost dokumentu vůči definovanému schématu, pokud dokument odpovídá, je označován jako platný (validní). 2 Způsoby ukládání XMLJazyk XML byl oficiálně uveden v roce 1998 a od té doby se velmi rychle rozšířil do mnoha různých oblastí a aplikací. S narůstající oblibou jazyka vyvstal problém s ukládáním a efektivním využíváním většího množství XML dat. Tato kapitola zjednodušeně ukazuje jednotlivé možnosti pro ukládání XML a měla by navrhnout vhodné řešení, které by bylo použitelné z pohledu vytvářeného metainformačního systému. 2.1 Ukládání do souboruNejjednodušší forma pro uložení XML je soubor, takovýto soubor lze dobře vizualizovat, uchovávat a distribuovat. Pro evidenci není potřeba žádné speciální vybavení. Veškeré operace týkající se zpracování musí řešit aplikační vrstva, při zpracování se musí načíst celý soubor. Možnost vyhledávání je velice omezená. Tato forma je vhodná pro přenos XML dat, popřípadě pro evidenci statických dat, kde je požadavek pouze na vizualizaci uložených dokumentů. 2.2 Ukládání prostřednictvím RSŘBDPro efektivnější uložení XML dat lze využít služeb RSŘBD, tímto krokem lze obohatit jednoduché uložení formou souboru o výhody databázové technologie, za zmínku stojí zejména víceuživatelský přístup a zabezpečení dat. Většina dnes dostupných RSŘBD alespoň nějakým způsobem podporuje prácí s XML. Buď je podpora XML přímo součásti produktu, nebo je dostupná jako přídavná komponenta. Podpora XML v relačních databázích se může nacházet ve dvou základních rovinách. První přístup pohlíží na XML jako na nový datový typ. XML dokument se ukládá do relační tabulky podobně jako jiné datové typy (do příslušného sloupce), tzn. jako komponenta v rámci řádku. Realizace způsobu uložení při této variantě záleží na konkrétním RSŘBD, ale v úvahu připadá uložit XML dokument buď jako dlouhý text, nebo jako segment binárních dat, popřípadě jako objektovou strukturu, pokud to daný systém umožňuje. Způsob indexace se odvíjí od způsobu uložení a možností jednotlivých RSŘBD. Při zpracování je ale nutné opět načíst celý dokument, výhodou je, že dokument lze získat zpět v nezměněné formě. Protože XML zde vystupuje jako datový typ, lze k manipulaci využít jazyk SQL, resp. jeho rozšíření o XML, toto rozšíření zpravidla realizuje výrobce RSŘBD. O standardizovaný způsob integrace XML do SQL se snaží pracovní skupina SQLX [22], která pracuje na rozšíření jazyka SQL. Druhý přístup je orientován spíše na data, která se v XML dokumentu nacházejí, samotný XML dokument je méně podstatný. Při této variantě je XML dokument rozložen podle definovaného algoritmu na sadu relačních tabulek. Uložení je z pohledu obsazeného místa méně hospodárné. Indexování a vyhledávání je realizováno standardním způsobem. Tento přístup je vhodný zejména pro často se měnící data. Zpětný proces, tj. z několika tabulek získat původní dokument může činit potíže, protože evidované informace o způsobu dekompozice nemusí být kompletní. Rekonstruovaný dokument tak nemusí přesně odpovídat původnímu dokumentu, což se může negativně projevit při vytvoření kontrolního součtu, např. pro potřeby elektronického podpisu. Tento přístup sebou nese také větší časovou náročnost, která souvisí s rozkladem a následným složením XML dokumentu [11]. 2.3 Nativní XML databázePosledně zmíněný problém umožňují řešit tzv. nativní XML databáze, které ukládají XML dokumenty v nativní formě a tudíž není potřeba provádět žádné mapování na relační strukturu. Jedná se o aplikace, které byly speciálně navrženy pro uchovávání XML dokumentů. Hlavním rysem je orientace na samotný XML dokument, nikoli na data, která dokument obsahuje. Mezi základní vlastnosti nativní XML databáze lze uvést. - Základní jednotkou je XML dokument, - dokumenty jsou organizovány v kolekcích, - při zpracování se nemusí načítat celý dokument, - dokument lze získat zpět v přesně takovém stavu, jak byl do systému vložen, - schopnost indexovat XML dokumenty s ohledem na stromovou strukturu, - implementace dotazovacího jazyka, kterým se lze dotazovat napříč kolekcemi, - podpora standardů souvisejících s XML, - implementace rozhraní pro komunikaci. Zdá se, že použití nativní XML databáze přináší samé výhody, je třeba ale upozornit na fakt, že tato oblast je poměrně mladá a stále se formuje, to se odráží i v oblasti standardizace a podpory. Ještě dnes není zcela jasné který dotazovací jazyk bude v budoucnu tím preferovaným. K dnešnímu dni se většinou pro dotazování používá jazyk XPath, který původně nevznikl jako čistokrevný XML dotazovací jazyk, ale jako podpůrný standard, který se používá v dalších standardech W3C, např. v XSLT. V budoucnu by měl být jazyk XPath nahrazen skutečným dotazovacím jazykem XQuery, některé komerční nativní XML databáze už XQuery implementují. Další problém souvisí s univerzálním přístupem k nativní XML databázi. Do nedávné doby se k přístupu využívalo pouze nativní API konkrétní databáze, to do jisté míry svazovalo aplikaci a použitou nativní XML databázi. To byl jeden z důvodů založení organizace XML:DB [34], která mimo jiné pracuje na standardizovaném rozhraní pro přístup k nativním XML databázím. Rozhraní se jmenuje XML:DB API a již existuje několik komerčních i nekomerčních databází, které toto rozhraní implementují. Jako důkaz toho, že definované rozhraní je použitelné, slouží produkty třetích stran, jako je např. XMLdbGUI , což je databázový klient, který umožňuje komunikovat s jakoukoli nativní XML databází, která nabízí rozhraní XML:DB API. Ukázku klienta XMLdbGUI, který je připojen k nativní XML databázi eXist ukazuje obr. 3, k dispozici jsou základní operace (import, export, vytváření a mazání kolekcí, dotazování pomocí jazyka XPath). Organizace XML:DB pracuje rovněž na standardu XUpdate, tento standard definuje syntaxi v XML, která zajišťuje aktualizaci XML dat. |
| Název prvku | Datový typ | Popis |
| Název | Řetězec | Název datové sady |
| Popis | Řetězec | Popis datové sady |
| Klasifikace | Slovník | Klíčem slovníků je kód tezauru, hodnotou je seznam termínů |
| Osoba - tvůrce | Seznam | Seznam obsahující jména a příjmení |
| Organizace - tvůrce | Seznam | Seznam obsahující názvy organizací |
| Platnost od | Řetězec | Datum představující časové rozlišení datové sady |
| Platnost do | Řetězec | Datum představující časové rozlišení datové sady |
| Pokrytí - území | Řetězec | Textové vyjádření plošného pokrytí datové sady |
| Pokrytí - polygon | Polygon | Geometrické vyjádření plošného pokrytí datové sady |
| Kód PRS | Řetězec | Kód prostorového referenčního systému, ke kterému se vztahuje prvek Pokrytí polygon |
Tab. 1 Struktura abstraktu
Pro navržené řešení kombinované evidence zmíněné v kap. 3.1 bylo potřeba stanovit strukturu abstraktu a dále převodní vztahy, které zajistí transformaci dostupných standardů na strukturu abstraktu. Touto transformací se zabývá tato kapitola.
Transformaci je vhodné vyjádřit ve formě tabulky, kde na každém řádku budou uvedeny odpovídající si prvky. Tato transformace může být vyjádřena obecně, jen názvy prvků, ale mnohem vhodnější je již vyjádřit tuto transformaci způsobem, který bude poplatný následné implementaci.
Tato etapa práce je samozřejmě závislá na dobré znalosti jednotlivých standardů, v rámci této práce bude stanoveno transformační schéma pouze pro standard ISVS. V případě přidání podpory pro další standard (např. FGDC, ISO) bude potřeba vypracovat odpovídající transformační schéma.
Následuje transformační tabulka (Tab. 2), která definuje způsob, jak aplikovat navrženou strukturu abstraktu na standard ISVS. Ekvivalent pro ISVS je vyjádřen výrazem v jazyce XPath, tento výraz koresponduje s definicí typu dokumentu (DTD), která popisuje výměnný formát metadat v jazyce XML.
| Abstrakt | ISVS (XPath) |
| Název | /METAIS/DATASET[1]/ OBJECT_STANDARD[@K_TYP_OBJ='DATASET']/@NAZEV |
| Popis | /METAIS/DATASET[1]/ OBJECT_STANDARD[@K_TYP_OBJ='DATASET']/@POPIS |
| Klasifikace - kód tezauru | /METAIS/DATASET[1]/ OBJECT_STANDARD[@K_TYP_OBJ='DATASET']/ OBJECT_STANDARD_KLASIF/@K_TEZAUR |
| Klasifikace - termín | /METAIS/DATASET[1]/ OBJECT_STANDARD[@K_TYP_OBJ='DATASET']/ OBJECT_STANDARD_KLASIF[@K_TEZAUR='CZKS']/ OBJECT_STANDARD_ID_TERM/@ID_TERM |
| Osoba - tvůrce - jméno | /METAIS/PERSON[@ID=identifikátor]/@JMENO |
| Osoba - tvůrce - příjmení | /METAIS/PERSON[@ID=identifikátor]/@PRIJMENI |
| Organizace - tvůrce | /METAIS/ORG[@ID=identifikátor]/@NAZEV" |
| Platnost od | /METAIS/DATASET[1]/ OBJECT_STANDARD[@K_TYP_OBJ='DATASET']/ @PLATN_OD |
| Platnost do | /METAIS/DATASET[1]/ OBJECT_STANDARD[@K_TYP_OBJ='DATASET']/@PLATN_DO |
| Pokrytí - území | /METAIS/DATASET[1]/ OBJECT_STANDARD[@K_TYP_OBJ='DATASET']/ @LOK_UZEMI |
| Pokrytí - polygon | /METAIS/DATASET[1]/ OBJECT_STANDARD[@K_TYP_OBJ='DATASET']/ OBJECT_STANDARD_LOK_POLY/MultiPolygon/ Polygon[1]/outerBoundaryIs/coordinates/text() |
| Kód PRS | /METAIS/DATASET[1]/OBJECT_STANDARD/ OBJECT_STANDARD_LOK_POLY/MultiPolygon/@srsName |
Tab. 2 Transformační tabulka pro standard ISVS
Metadata o prostorových datech jsou mimo jiné specifická také tím, že musí obsahovat prvky stanovující plošné pokrytí datové sady, tato informace může být vhodným kritériem při požadavcích na vyhledání potřebných dat.
Dostupné jsou následující možnosti prostorového vyhledávání.
- Výběr všech datových sad, které svým plošným pokrytím spadají kompletně do oblasti výběrového obdélníku (Obr. 5)
- Výběr všech datových sad, které svým plošným pokrytím spadají kompletně, nebo částečně do oblasti výběrového obdélníku (Obr. 5)
- Výběr všech datových sad, které obsahují výběrový bod
ve svém plošném pokrytí (Obr. 6)
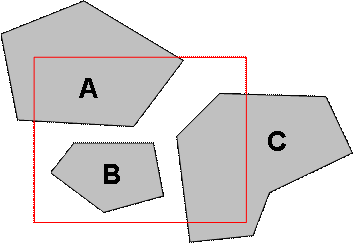
Obr. 5 Prostorový dotaz na plošné pokrytí datových sad prostřednictvím výběrového obdélníku
Při první variantě dotazu prostřednictvím výběrového obdélníku budou ve výsledku zahrnuty pouze takové datové sady, jejichž plošné pokrytí padne celé do oblasti výběrového obdélníku (Plošný rozsah B), druhá varianta dotazu zahrne do výsledku navíc také datové sady, které svým plošným pokrytím spadají jen částečně do oblasti výběrového obdélníku (Plošné rozsahy A, C).
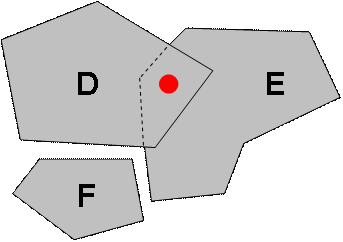
Obr. 6 Prostorový dotaz na plošné pokrytí datových sad prostřednictvím výběrového bodu
Pokud je prostorový dotaz specifikován výběrovým bodem (Obr. 6), potom výsledek bude obsahovat všechny datové sady, které obsahují výběrový bod ve svém plošném pokrytí (Plošné rozsahy D, E).
Objektově orientovaná analýza si klade za cíl vytvořit logickou strukturu systému, která bude schopna splnit specifikované požadavky. V úvodu jsou zmíněny požadavky na vytvářený systém, tyto požadavky se dělí na požadavky funkční a požadavky nefunkční, které závisí na okolnostech nesouvisejících s analýzou řešeného problému. Obchodní logika systému je nastíněna ve formě diagramů aktivit. Doménový model mapuje vztahy mezi pojmy, které se v této fázi v analýze vyskytly. Model případu užití popisuje jednotlivé charakteristické úlohy, které systém bude realizovat. Každý případ užití uvádí i textový popis posloupnosti kroků, které vedou k naplnění případu užití. Model analýzy uvádí zejména diagram analytických tříd a realizace případů užití. Pro zachycení realizací případů užití jsou uvedeny sekvenční diagramy a diagramy spolupráce. Realizovaný postup objektově orientované analýzy vychází z metodiky UP (Unified Process) a využívá notace UML (Unified Modeling Language) [2].
Kapitola Programové vybavení navazuje na kapitolu Objektově orientovaná analýza a definuje tak implementační prostředí, které je nezbytné pro vstup do etapy objektově orientovaný návrh, kde se již projeví přechod od logické struktury aplikace do fyzické, realizovatelné podoby, závislé na konkrétních softwarových komponentách. Při výběru programových produktů bylo přihlíženo k následujícím kritériím.
- Pro implementaci použít plně objektově orientované technologie
- Zajistit rychlý vývoj funkčního prototypu
- Dosáhnout přehlednosti, udržitelnosti a rozšiřitelnosti aplikace jako celku
- Umožnit spolupráci s dalšími aplikacemi
- Finanční dostupnost
Dále bude zmíněn vždy programový produkt, jeho krátké představení a důvody pro jeho nasazení, zmínění výhod, nevýhod, popřípadě alternativní programový produkt.
Jako operační systém byl zvolen MS Windows 2000 Professional, výsledná aplikace je ale na tomto systému nezávislá, a může po malých úpravách být provozována na jiném operačním systému. Pro další výklad se bude předpokládat platforma MS Windows, a tudíž všechny ostatní komponenty budou popsány s ohledem na tento operační systém. Mezi výhody lze zařadit jednoduchý postup při instalaci nového programového vybavení, nevýhodou je, že produkt není dostupný zdarma.
Jako programovací jazyk byl zvolen jazyk Python, jedná se o plně objektově orientovaný skriptovací jazyk, který je vhodný jak pro psaní jednoduchých skriptů, tak i rozsáhlých aplikací. Důvodem pro nasazení tohoto jazyka je také možnost využít jej v rámci přizpůsobení aplikačního serveru. Má automatickou správu paměti a dynamické typování. Pro tvorbu GUI lze využít některou s externích knihoven např. TCL/TK. Jazyk Python vyniká velice úspornou syntaxí, takže zkušený programátor může dosáhnout stanoveného cíle jen s minimálním množstvím kódu. Jazyk je vysoce modulární a nabízí pestrou nabídku datových typů, resp. objektů. Zdrojový kód je možné přeložit do bajtového kódu, čímž se urychlí běh aplikace. Python lze použít ve spolupráci s jinými programovacími jazyky, např. Javou, dokonce lze zdrojový kód v Pythonu zkompilovat do bajtového kódu jazyka Java (JPython). Pro systém Windows lze vytvářet spustitelné EXE soubory, rovněž existuje rozšíření pro využití technologie COM/DCOM. Jazyk Python je svázán s jazyky C/C++, a lze jej pomocí těchto jazyků dále rozšiřovat, nebo přímo volat knihovny v C/C++.
Největším přínosem zvoleného programovacího jazyka je velice rychlá tvorba aplikací, která je dána úspornou syntaxí a dynamickým typováním. Snadná tvorba modulů umožňuje vytvářet i velice rozsáhlé a přitom přehledně členěné aplikace. Jazyk Python je zcela zdarma a součástí instalace jsou i zdrojové kódy. Nepatrnou nevýhodou je časově náročnější provádění kódu, které je odůvodněno dynamickým typováním a interpretováním, ale při tvorbě prototypového řešení lze tento nedostatek zcela zanedbat [3], [12], [8].
Využitím aplikačního serveru lze elegantně naplnit některá dříve nastíněná kritéria, hlavním posláním aplikačního serveru je zjednodušení správy webové aplikace, a ulehčení práce při vývoji aplikace. Vývojář se tak může koncentrovat na jádro problému a nemusí řešit sekundární problémy, které souvisí s tvorbou webových aplikací, jako je správa uživatelů, zabezpečení, oddělení obchodní logiky a prezentační vrstvy, správa datových zdrojů popř. týmovou spolupráci. Využití aplikačního serveru má rovněž vliv na přehlednost, udržitelnost a rozšiřitelnost aplikace.
Jako aplikační server byl zvolen aplikační server Zope, který je kompletně založen na jazyku Python, a pomocí tohoto jazyka může být dále rozšiřován. Aplikační server Zope se skládá z několika součástí.
- WWW server
- Webové rozhraní pro řízení aplikačního serveru
- Objektová databáze
- Konektory na RSŘBD
- Skriptovací jazyk
Mezi důležité rysy tohoto aplikačního serveru patří komponentová architektura, která umožňuje tvorbu vlastních komponent a tím dále rozšiřovat funkčnost. Zajímavým rysem je způsob ukládání dat pomocí vlastního souborového systému, který je realizovaný formou interní objektové databáze, nebo externím RSŘBD. Díky tomuto způsobu ukládání dat je možné k datům přistupovat efektivněji pomocí objektově orientovaných konceptů. Například obyčejná HTML stránka může být v systému uložena jako objekt, ke kterému lze definovat až 29 různých přístupových práv.
Jako prezentační nástroj využívá Zope techniku šablon, která umožňuje oddělit programový kód a vzhled. Šablona zachycuje výsledný vzhled stránky a zároveň zajišťuje volání skriptů, které řeší logiku aplikace. Skripty jsou psány v jazyce Python.
Největším přínosem je celistvé vývojové prostředí, které plně dostačuje pro tvorbu i rozsáhlejších webových aplikací. K dispozici je vše potřebné, mechanizmus pro ukládání dat, prezentační vrstva a webové rozhraní, pomocí kterého lze aplikační server řídit, ale i programovat. Programování aplikačního serveru přes WWW rozhraní, může být značná výhoda, ale také nevýhoda. Uživatelský komfort desktop aplikace při vývoji lze prostředky WWW klienta těžko docílit. Zope je zdarma a dodáván včetně zdrojových kódů.
Jako nativní XML databáze byl zvolen produkt eXist. Jedná se o aplikaci vytvořenou v jazyce Java. Jako dotazovací jazyk je využit XPath 1.0, který je doplněn o několik málo instrukcí pro fulltextové vyhledávání. Aplikace má propracovaný systém indexování XML dokumentů, který je optimalizován pro dotazy v jazyce XPath. Indexují se textové hodnoty elementů, ale i topologie elementů. Aplikace podporuje XUpdate, což je standard pro aktualizaci specifikované části XML dokumentu.
Databáze eXist nabízí bohatou nabídku rozhraní pro komunikaci. Jedná se o možnost komunikovat přes XML-RPC, WebDAV, SOAP a pro vývojáře v jazyce Java i přes
XML:DB API, způsob komunikace se odvíjí od varianty, ve které je eXist provozován. Dostupné jsou tři možnosti.
- Samostatný serverový proces, eXist využívá vlastní JVM (Java Virtual Machine)
- eXist je přímo součástí klientské aplikace (tzv. embedded mód), klient i databáze využívají stejný JVM
- Webová aplikace využívající technologii servlet
Databáze eXist využívá těsné spolupráce s aplikací Apache Cocoon, která je součástí instalace. Tato vrstva je vhodná pro obecnou transformaci XML dokumentů. Integrace těchto dvou aplikací je založena na standardu XML:DB.
Výhodou databáze eXist je široká paleta komunikačních rozhraní, dále implementace dotazovacího jazyka XPath 1.0. Součástí instalace je i databázový klient dostupný jako desktop aplikace, nebo WWW klient. Výhodou je integrace s aplikací Apache Cocoon, která umožňuje jednoduše vizualizovat uložené XML dokumenty pomocí jazyka XSLT.
Pro podporu práce s XML daty byla použita knihovna PyXML, která realizuje množinu standardních operací s XML, jedná se především o analyzátory kódu založené na API DOM, případně SAX. Pro podporu práce s geometrickou složkou dat byla využita knihovna Polygon, která řeší základní operace s polygony, jedná se např. o výpočet obsahu, stanovení centroidu, stanovení vymezujícího obdélníku, logické operace s polygony apod. Obě knihovny se instalují dodatečně jako rozšíření programovacího jazyka Python. Následující tabulka (Tab. 3) shrnuje použité programové vybavení vyjma operačního systému.
| Název | Popis | Verze | Domovská stránka produktu |
| Python | Interpret jazyka Python, knihovny jazyka, jednoduché vývojové prostředí | 2.2.2003 | http://www.python.org |
| PyXML | Knihovna pro práci s XML daty | 0.8.1 | http://pyxml.sourceforge.net/ |
| Polygon | Knihovna pro efektivní práci s polygony | 1.0.1 |
http://www.dezentral.de/ warp.html |
| Zope | Aplikační server | 2.7.0-b2 | http://www.zope.org |
| eXist | Nativní XML databáze, pro provoz je potřeba interpret jazyka Java (SDK verze 1.4) | 0.9.2 | http://exist-db.org |
Tab. 3 Použité programové vybavení
Cílem objektově orientovaného návrhu je vytvoření návrhového modelu, který bude již možné implementovat. Návrhový model upřesňuje a rozvíjí analytický model s důrazem na implementační prostředí.
V procesu návrhu dochází k upřesnění analytických tříd, toto upřesnění se projeví zejména přechodem od analytických operací k návrhovým metodám, tzn. každá analytická operace musí být nahrazena množinou návrhových metod, která zajistí požadované chování. Upřesnění se může dále projevit rozkladem analytické třídy na několik návrhových tříd, popřípadě návrhem rozhraní. V této etapě se rovněž projeví namapování logické struktury aplikace na již existující softwarové komponenty.
Etapa implementace se zabývá tvorbou spustitelného kódu, který je vytvářen na základě výstupů etapy návrhu. Jednotlivé návrhové třídy byly implementovány v čistém jazyce Python, navigace a GUI byly vytvořeny přímo v prostředí aplikačního serveru Zope technikou šablon a skriptů. V rámci této kapitoly budou zmíněny pouze stěžejní části, které jsou z pohledu implementace zajímavé, jedná se o následující oblasti.
- Grafické uživatelské rozhraní
- Přidání podpory pro další standard
- Komunikace s nativní XML databází
- Přizpůsobení ZCatalogu
Primárním výstupem této diplomové práce je prototyp metainformačního systému pro prostorová data, který eviduje metadata ve formě XML dokumentů. Postup tvorby systému shrnuje v chronologickém pořadí následující přehled jednotlivých kapitol diplomové práce.
Kapitola 1 Základní pojmy seznamuje čtenáře s problematikou, která blízce souvisí s tématem diplomové práce. V úvodu je vysvětlen pojem metadata. Je naznačen význam a důležitost evidence metadat. Rovněž je uvedeno základní dělení metadat a představena struktura metadat pro prostorová data s vazbou na příslušné národní a mezinárodní standardy. Dále jsou zmíněny typické vlastnosti metainformačních systémů a jejich základní dělení. V závěru kapitoly je představen jazyk XML a související technologie, které byly při tvorbě prototypu využity.
Kapitola 2 Způsob uložení XML předkládá dostupné možnosti pro uložení XML. Uvedeno je ukládání do souboru, ukládání prostřednictvím RSŘBD, využití nativní XML databáze a jiná řešení. Jednotlivé možnosti jsou stručně představeny. Na základě kritérií, která plynou z požadavků na ukládání XML z pohledu metainformačního systému byla zvolena varianta využívající nativní XML databázi.
Kapitola 3 Kombinovaná evidence metadat podle různých standardů se zabývá nalezením takového řešení, které umožní evidovat metadata podle různých standardů a to v rámci jednoho systému. Nejprve je zmíněna problematika kombinované evidence a zejména vyhledávání v datech různé struktury. Navržené řešení je založeno na využití jednotících prvků, které se dají identifikovat ve všech uvažovaných standardech. Tyto prvky se označují jako core metadata. Pro naplnění tohoto přístupu musela být definována struktura základních metadatových prvků a způsob, jakým tuto strukturu naplnit. Výstupem této kapitoly je tedy definovaná struktura základních metadatových prvků, která byla funkčně označena jako abstrakt. A dále transformační tabulka, která říká, jak převést metadatový záznam podléhající standardu ISVS na definovaný abstrakt. Tímto krokem byla vyřešena nekompatibilita standardů v procesu kombinované evidence.
Kapitola 4 Prostorové vyhledávání upozorňuje na specifický aspekt metadat pro prostorová data a to na plošné pokrytí datové sady. Tento aspekt je vhodným kritériem při vyhledání potřebných dat. Byly definovány tři prostorové dotazy. Dvě varianty výběrového obdélníku a výběrový bod. V závěru kapitoly jsou naznačeny problémy optimalizace prostorového vyhledávání a způsoby získání parametrů prostorových dotazů.
Kapitola 5 Objektově orientovaná analýza XML metainformačního systému ukazuje logický pohled na navržený systém. Byly definovány funkční a nefunkčních požadavky, které má systém splňovat. Formou diagramů aktivit jsou uvedeny základní činnosti, které byly v systému identifikovány. Doménový model popisuje vztahy mezi pojmy problémové domény. Typické úlohy systému jsou prezentovány pomocí případů užití a to jednak graficky a také pomocí slovní specifikace. Byly navrženy jednotlivé analytické třídy a sestaven diagram analytických tříd. Správnost navržené struktury byla ověřena pomocí případů užití realizovaných formou sekvenčních diagramů.
Kapitola 6 Programové vybavení definuje na základě uvedených kritérií implementační prostředí. Programovacím jazykem byl zvolen Python, jedná se o velice efektivní jazyk, který umožňuje rychlý vývoj prototypu. Pro podporu tvorby a zejména správy webové aplikace byl využit aplikační server Zope, který v kombinaci s jazykem Python vytváří celistvé, plně objektově orientované vývojové prostředí. Pro nezávislé uložení XML byla použitá nativní XML databáze eXist.
Kapitola 7 Objektově orientovaný návrh se zabývá tvorbou návrhové modelu. Návrhový model upřesňuje a rozvíjí analytický model v rámci možností implementačního prostředí. Návrhové třídy jsou již konkretizovány do podoby, která dovoluje implementaci.
Kapitola 8 Implementace popisuje tvorbu spustitelného kódu a upozorňuje na některé zajímavé implementační rysy. Zejména je vysvětlena tvorba GUI v prostředí aplikačního serveru. Pro komunikaci mezi aplikačním serverem a databází byl využit protokol XML-RPC, důvodem je programová nekompatibilita zmíněných součástí. V rámci kapitoly byl naznačen postup při implementaci podpory pro nový standard.
Mezi výhody XML metainformačního systému lze uvést, že není potřeba definovat datový model pro ukládání metadat. Rovněž není potřeba implementovat mechanizmus pro import a export metadat ve výměnném formátu, protože metadata jsou ukládána přímo v nativní podobě. Další výhodou je vizualizace metadat, která je založena na XML standardech a je plně řízena daty.
1. AALDERS, Henri. Data searching by metadata [online]. In Sborník z konference GIS Ostrava 2001, Ostrava, 2001 [cit. 2004-01-01]. Dostupné na WWW: <http://gis.vsb.cz/Publikace/Sborniky/GIS_Ova/gis_ova_2001/sbornik/Referaty/aalders.htm>
2. ARLOW, Jim, a NEUSTADT, Ila. UML a unifikovaný proces vývoje aplikací : Průvodce analýzou a návrhem objektově orientovaného softwaru. 1. vyd. Brno : Computer Press, 2003. 387 stran. ISBN 80-7226-947-X
3. BEAZLEY, David, M. Python : Podrobná referenční příručka pro programovací jazyk Python. 1. vyd. Praha : Neocortex, spol. s r. o., 2002. 429 stran. ISBN 80-86330-05-2
4. DCMI. Dublin Core Metadata Initiative [online]. Dostupné na WWW: <http://dublincore.org>
5. DUCHOSLAV, Tomaš. Tvorba metainformačního systému pro prostorová data s
využitím internetových technologií. Diplomová práce obhájená na
Hornicko-geologické fakultě
VŠB TU Ostrava r. 2002. 72 stran. Depon. in: VŠB
TU Ostrava, Ústřední knihovna, Ostrava.
6. FGDC. Content Standard for Digital Geospatial Metadata [online]. 1998 [cit. 2004-01-01]. Dostupné na WWW: <http://www.fgdc.gov/metadata/contstan.html>
7. FGDC. Federal Geographic Data Committee [online]. Dostupné na WWW: <http://www.fgdc.gov>
8. HARMS, Daryl, a MCDONALD, Kenneth. Začínáme programovat v jazyce Python. 1. vyd. Brno : Computer Press, 2003. 456 stran. ISBN 80-7226-799-X
9. HOLZNER, Steven. XSLT příručka internetového vývojáře. 1. vyd. Praha : Computer Press, 2002. 515 stran. ISBN 80-7226-600-4
10. ISO. ISO [online]. Dostupné na WWW: <http://www.iso.org>
11. KOSEK, Jiří. Ukládání a vyhledávání XML dat [online]. 2002 [cit. 2004-01-01]. Dostupné na WWW: <http://badame.vse.cz/izi238/slidy/ql/titlepg.html>
12. LUTZ, Mark, a ASCHER, David. Naučte se Python : Pohotová příručka. 1. vyd. Praha : Computer Press, 2003. 360 stran. ISBN 80-247-0367-X
13. MARCHAL, Benoit. XML v příkladech. 1. vyd. Praha : Computer Press, 2000. 447 stran. ISBN 80-7226-332-3
14. MI. Standard ISVS pro strukturu a výměnný formát metadat informačních
zdrojů, verze 1.1 [online]. 2002 [cit. 2004-01-01]. Dostupné na WWW:
<http://www.micr.cz/dokumenty/
koordinace.htm>
15. OGC. Geography Markup Language (GML) Implementation Specification [online]. 2003 [cit. 2004-01-01]. Dostupné na WWW: <http://www.opengis.org/docs/02-023r4.pdf>
16. OGC. Open GIS Consortium [online]. Dostupné na WWW: < http://www.opengis.org>
17. OGC. Simple Features Specification For SQL [online]. 1999 [cit. 2004-01-01]. Dostupné na WWW: < http://www.opengis.org/docs/99-049.pdf>
18. POKORNÝ, Jaroslav. Prostorové datové struktury a jejich použití k
indexaci prostorových objektů [online]. In Sborník z konference GIS Ostrava
2000, Ostrava,
2000 [cit. 2004-01-01]. Dostupné na WWW: <http://gis.vsb.cz/Publikace/Sborniky/GIS_Ova/gis_ova_2000/sbornik/Pokorny/Referat.htm>
19. POKORNÝ, Jaroslav. Prostorové objekty a SQL [online]. In Sborník z konference GIS Ostrava 2001, Ostrava, 2001 [cit. 2004-01-01]. Dostupné na WWW: <http://gis.vsb.cz/Publikace/Sborniky/GIS_Ova/gis_ova_2001/sbornik/Referaty/Pokornyr.htm>
20. RŮŽIČKA, Jan. Metadata pro prostorová data. Disertační práce obhájená na Hornicko-geologické fakultě VŠB TU Ostrava r. 2002. 160 stran. Depon. in: VŠB TU Ostrava, Ústřední knihovna, Ostrava.
21. SAXPROJECT. Simple API for XML [online]. 1999 [cit. 2004-01-01]. Dostupné na WWW:<http://www.saxproject.org/>
22. SQLX. SQLX [online]. Dostupné na WWW: <http://www.sqlx.org>
23. TRAVIS, Brian, E. XML a SOAP : Programování serverů BizTalkTM. 1. vyd. Praha : Computer Press, 2000. 418 stran. ISBN 80-7226-303-X
24. UDDI. Universal Description, Discovery and Integration [online]. Dostupné na WWW:<http://www.uddi.org/>
25. USERLAND. XML-RPC [online]. 1999 [cit. 2004-01-01]. Dostupné na WWW:<http://www.xmlrpc.com/spec>
26. W3C. Document Object Model, Level 2, version 1.0 [online]. 2000 [cit. 2004-01-01]. Dostupné na WWW: <http://www.w3.org/TR/2000/REC-DOM-Level-2-Core-20001113>
27. W3C. Extensible Markup Language, version 1.0 (Third Edition) [online]. 2004 [cit. 2004-04-19]. Dostupné na WWW: <http://www.w3.org/TR/REC-xml-20040204>
28. W3C. Extensible Stylesheet Language Transformation, version 1.0 [online]. 1999 [cit. 2004-01-01]. Dostupné na WWW: <http://www.w3.org/TR/xslt>
29. W3C. HyperText Markup Language 4.01 [online]. 1999 [cit. 2004-01-01]. Dostupné na WWW: <http://www.w3.org/TR/html40/>
30. W3C. Simple Object Access Protocol, version 1.2 [online]. 2003 [cit. 2004-01-01]. Dostupné na WWW: <http://www.w3.org/TR/2003/REC-soap12-part0-20030624>
31. W3C. Web Service Definition Language, version 2.0 [online]. 2004 [cit. 2004-04-19]. Dostupné na WWW: <http://www.w3.org/TR/wsdl20>
32. W3C. XML Schema Definition [online]. 2001 [cit. 2004-01-01]. Dostupné na WWW: <http://www.w3.org/TR/xmlschema>
33. W3C. XPath, version 1.0 [online]. 1999 [cit. 2004-01-01]. Dostupné na WWW: <http://www.w3.org/TR/xpath>
34. XML:DB. XML:DB [online]. Dostupné na WWW: <http://www.xmldb.org>
|
Copyright (C) VŠB - TU Ostrava,
Institut geoinformatiky, 2001-3. Všechna práva vyhrazena. |